00:00 Introduction
02:52 Background and disclaimer
07:39 Naïve rationalism
13:14 The story so far
16:37 Scientists, we need you!
18:25 Human + Machine (the problem 1/4)
23:16 The setup (the problem 2/4)
26:44 The maintenance (the problem 3/4)
30:02 The IT backlog (the problem 4/4)
32:56 The mission (the job of the scientist 1/6)
35:58 Terminology (the job of the scientist 2/6)
37:54 Deliverables (the job of the scientist 3/6)
41:11 The scope (the job of the scientist 4/6)
44:59 Daily routine (the job of the scientist 5/6)
46:58 Ownership (the job of the scientist 6/6)
49:25 A supply chain position (HR 1/6)
51:13 Hiring a scientist (HR 2/6)
53:58 Training the scientist (HR 3/6)
55:43 Reviewing the scientist (HR 4/6)
57:24 Retaining the scientist (HR 5/6)
59:37 From one scientist to the next (HR 6/6)
01:01:17 On IT (corporate dynamics 1/3)
01:03:50 On Finance (corporate dynamics 2/3)
01:05:42 On Leadership (corporate dynamics 3/3)
01:09:18 Old-school planning (modernization 1/5)
01:11:56 End of S&OP (modernization 2/5)
01:13:31 Old-school BI (modernization 3/5)
01:15:24 Exit Data Science (modernization 4/5)
01:17:28 A new deal for IT (modernization 5/5)
01:19:28 Conclusion
01:22:05 7.3 The Supply Chain Scientist - Questions?
Description
At the core of a Quantitative Supply Chain initiative, there is the Supply Chain Scientist (SCS) who executes the data preparation, the economic modeling and the KPI reporting. The smart automation of the supply chain decisions is the end-product of the work done by the SCS. The SCS takes ownership of the generated decisions. The SCS delivers human intelligence magnified through machine processing power.
Full transcript

Welcome to this series of supply chain lectures. I am Joannes Vermorel, and today I will be presenting the supply chain scientist from the perspective of the quantified supply chain. The supply chain scientist is the person or possibly the small group of persons in charge of spearheading the supply chain initiative. This person oversees crafting and later maintaining the numerical recipes that generate the decisions of interest. This person is also in charge of providing all the necessary evidence to the rest of the company, proving that the generated decisions are sound.
The motto of the quantified supply chain is to make the most of what modern hardware and modern software have to offer to supply chains. However, the incarnate flavor of this perspective is naive. Human intelligence is still a cornerstone of the whole undertaking and due to a variety of reasons cannot yet be nicely packaged as far as a supply chain is concerned. The goal of this lecture is to understand why and how the role of the supply chain scientist has become, during the last decade, a time-tested solution to make the most of modern software for supply chain purposes.
Achieving this goal starts with understanding the great bottlenecks that modern software is still facing when attempting to automate supply chain decisions. Based on this newfound understanding, we will introduce the role of the supply chain scientist, which is, for all intents and purposes, an answer to those bottlenecks. Finally, we will see how this role reshapes, in small and bigger ways, the company as a whole. Indeed, the supply chain scientist cannot operate as a silo within the company. Just like the scientist must cooperate with the rest of the company to achieve anything, the rest of the company must also cooperate with the scientist for this to happen.

Before proceeding any further, I would like to reiterate a disclaimer that I made in the very first lecture of this series. The present lecture is almost entirely based on a somewhat unique decade-long experiment conducted at Lokad, an enterprise software vendor that specializes in supply chain optimization. All these lectures have been shaped by the journey of Lokad, but when it comes to the role of the supply chain scientist, the bond is even stronger. To a large extent, the journey of Lokad itself can be read through the lenses of our gradual discovery of the role of the supply chain scientist.
This process is still ongoing. For example, we only gave up about five years ago on the mainstream data scientist perspective with the introduction of programming paradigms for learning and optimization purposes. Lokad presently employs three dozen supply chain scientists. Our most capable scientists, through their track records, have become trusted with decisions on a large scale. Some of them are individually responsible for parameters that exceed half a billion dollars’ worth of inventory. This trust extends to a wide variety of decisions, such as purchase orders, production orders, inventory allocation orders, or pricing.
As you might surmise, this trust had to be earned. Indeed, very few companies would even trust their own employees with such powers, let alone a third-party vendor like Lokad. Earning this degree of trust is a process that typically takes years, irrespective of the technological means. Yet, a decade later, Lokad is growing faster than it ever did in its early years, and a sizable portion of this growth comes from our existing customers who are widening the scope of the decisions trusted to Lokad.
This brings me back to my initial point: this lecture almost certainly comes with all sorts of biases. I have tried to broaden this perspective through similar experiences outside Lokad; however, there is not much to be told on that front. To my knowledge, there are a few tech giant companies, more specifically a few giant e-commerce companies, that achieve a degree of decision automation that is comparable to the one that Lokad achieves.
However, these giants typically allocate two orders of magnitude more resources than what regular large companies can afford, with engineering headcounts in the hundreds. The feasibility of these approaches remains unclear to me, as they may only work in exceedingly profitable companies. Otherwise, the staggering payroll costs may very well exceed the benefits brought by better supply chain execution.
Furthermore, attracting engineering talent on such a scale becomes a challenge of its own. Hiring one talented software engineer is difficult enough; hiring 100 of them requires a fairly remarkable employer brand. Fortunately, the perspective presented today is much leaner. Many supply chain initiatives carried out by Lokad are done with a single supply chain scientist, with a second one acting as a substitute.Beyond payroll savings, our experience indicates that there are substantial supply chain benefits associated with a smaller headcount.

The mainstream supply chain perspective adopts the stance of applied mathematics. Methods and algorithms are presented in a manner that removes the human operator from the picture entirely. For example, the safety stock formula and the economic order quantity formula are presented as a pure matter of applied mathematics. The identity of the person wielding these formulas, their skills, or their background, for example, is not only inconsequential but is not even part of the presentation.
More generally, this stance is largely adopted in supply chain textbooks and consequently in supply chain software. It certainly feels more objective to remove the human component from the picture. After all, the validity of a theorem does not depend on the person enunciating the proof, and likewise, the performance of an algorithm does not depend on the person who ends up pressing the last keystroke of its implementation. This approach aims to achieve a superior form of rationality.
However, I argue that this stance is naive and represents yet another instance of naive rationalism. My proposition is subtle yet important: I am not arguing that the outcome of a numerical recipe depends on the person who ultimately runs the recipe, nor that the character of a mathematician has anything to do with the validity of their theorems. Instead, my proposition is that the intellectual stance associated with this perspective is inappropriate for approaching supply chains.
A real-world supply chain recipe is a complex piece of craftsmanship, and the author of the recipe is not nearly as neutral or irrelevant as it may seem. Let’s illustrate this point by considering two identical numerical recipes that only differ in the naming of their variables. At the numerical level, the two recipes deliver identical outputs. However, the first recipe has well-chosen, meaningful variable names, while the second recipe has cryptic, inconsistent names. In production, the second recipe (the one with cryptic, inconsistent variable names) is a disaster waiting to happen. Every evolution or bug fix applied to the second recipe will cost orders of magnitude more effort compared to the same task accomplished on the first recipe. In fact, variable naming issues are so frequent and severe that many software engineering textbooks dedicate an entire chapter to this single question.
Neither mathematics, algorithmics, nor statistics say anything about the adequacy of variable names. The adequacy of those names lies obviously in the eye of the beholder. Although we have two numerically identical recipes, one is deemed far superior to the other for seemingly subjective reasons. The proposition I am defending here is that there is rationality to be found in those subjective concerns as well. These concerns should not be dismissed outright for being dependent on a subject or person. On the contrary, Lokad’s experience indicates that given the same software tools, mathematical instruments, and library of algorithms, certain supply chain scientists achieve superior results. In fact, the identity of the scientist in charge is one of the best predictors we have for the success of the initiative.
Assuming that innate talent cannot entirely explain the discrepancies in supply chain success, we should embrace the elements that contribute to successful initiatives, whether they are objective or subjective. This is why, at Lokad, we have put a lot of effort during the last decades into refining our approach to the role of the supply chain scientist, which is precisely the topic of this lecture. The nuances associated with the position of a supply chain scientist should not be underestimated. The magnitude of improvements brought by these subjective elements is comparable to our most notable technological achievements.
This series of lectures is intended as training material for Lokad’s supply chain scientists. However, I also hope that these lectures may be of interest to a wider audience of supply chain practitioners or even supply chain students. It’s best to watch these lectures in sequence for a thorough understanding of what supply chain scientists are dealing with.
In the first chapter, we have seen why supply chains must become programmatic and why it is highly desirable to be able to put a numerical recipe in production. The ever-increasing complexity of supply chains makes automation more pressing than ever. In addition, there is a financial imperative to make supply chain practices capitalistic.
The second chapter is dedicated to methodologies. Supply chains are competitive systems, and this combination defeats naive methodologies. The role of scientists can be seen as an antidote to the naive applied mathematics methodology.
The third chapter surveys the problems faced by supply chain personnel. This chapter attempts to characterize the classes of decision-making challenges that have to be addressed. It shows that simplistic perspectives like picking the right stock quantity for every SKU don’t fit real-world situations; there is invariably depth in the form of decision-making.
The fourth chapter surveys the elements required to apprehend a modern practice of supply chain, where software elements are ubiquitous. These elements are fundamental to understanding the broader context in which the digital supply chain operates.
Chapters 5 and 6 are dedicated to predictive modeling and decision-making, respectively. These chapters cover the “smart” bits of the numerical recipe, featuring machine learning and mathematical optimization. Notably, these chapters collect techniques that have been found to work well in the hands of supply chain scientists.
Finally, the seventh and present chapter is dedicated to the execution of a quantitative supply chain initiative. We have seen what it takes to kick off an initiative while laying out the proper foundations. We have seen how to cross the finish line and put the numerical recipe in production.

Today, we will see what sort of person it takes to make the whole thing happen.
The role of the scientist aims to solve problems found in academic literature. We will review the job of the supply chain scientist, including their mission, scope, daily routine, and items of interest. This job description reflects the present-day practice at Lokad.
A new position within the company creates a series of concerns, so scientists need to be hired, trained, reviewed, and retained. We will approach these concerns from a human resources perspective. The scientist is expected to cooperate with other departments within the company beyond their supply chain department. We’ll see what sort of interactions are expected between the scientists and IT, finance, and even company leadership.
The scientist also represents an opportunity for the company to modernize its staff and operations. This modernization is the most difficult part of the journey, as it is far more challenging to remove a position that has ceased to be relevant rather than introducing a new one.
The challenge we have set for ourselves in this series of lectures is the systematic improvement of supply chains through quantitative methods. The general gist of this approach is to make the most of what modern computing and software have to offer to supply chains. However, we need to clarify what still belongs to the realm of human intelligence and what can be successfully automated.
The line of demarcation between human intelligence and automation is still very much dependent on technology. Superior technology is expected to mechanize a broader spectrum of decisions and deliver better outcomes. From a supply chain perspective, this means taking more diverse decisions, such as pricing decisions in addition to inventory replenishment decisions, and producing better decisions that further improve the profitability of the company.
The role of the scientist is the embodiment of this frontier between human intelligence and automation. While routine announcements about artificial intelligence may give the impression that human intelligence is on the verge of being automated away, my understanding of the state of the art indicates that general artificial intelligence remains distant. Indeed, human insights are still very much needed when it comes to the design of quantitative methods of supply chain relevance. Establishing even a basic supply chain strategy remains largely beyond the realm of what software can deliver.
More generally, we don’t yet have technologies capable of tackling badly framed problems or unidentified problems, which are commonplace in supply chain. However, once a narrow, well-specified problem has been isolated, it is conceivable to have an automated process learn its resolution and even automate this resolution with little or no human oversight.
This perspective is not novel. For example, anti-spam filters have become broadly adopted. Those filters accomplish a challenging task: sorting the relevant from the irrelevant. However, the design of the next generation of filters is still largely left to humans, even if newer data can be used to update those filters. Indeed, spammers who want to circumvent anti-spam filters keep inventing new methods that defeat plain data-driven updates of those filters.
Thus, while human insights are still needed to engineer the automation, it is not clear why a software vendor like Lokad, for example, could not engineer a grand supply chain engine that would address all these challenges. Certainly, the economics of software are very much in favor of engineering such a grand supply chain engine. Even if the initial investment is steep, as software can be replicated at a negligible cost, the vendor will make a fortune in licensing fees by reselling this grand engine to a large number of companies.
Lokad, back in 2008, did embark on such a journey of creating a grand engine that could have been deployed as a packaged software product. More precisely, Lokad was at that time focusing on a grand forecasting engine rather than a grand supply chain engine. Yet, despite these comparatively more modest ambitions, as forecasting is only a small portion of the global supply chain challenge, Lokad failed at creating such a grand forecasting engine. The quantitative supply chain perspective presented in this series of lectures arose from the ashes of this grand engine ambition.
Supply chain-wise, it turned out that there are three great bottlenecks to be addressed. We will see why this grand engine was doomed from day one and why we are still most likely decades away from such an engineering feat.
The applicative landscape of the typical supply chain is a jungle that has grown haphazardly over the last two or three decades. This landscape is not a French formal garden with neat geometrical lines and well-trimmed bushes; it’s a jungle, both vibrant but also full of thorns and hostile fauna. More seriously, supply chains are the product of their digital history. There might be multiple semi-redundant ERPs, half-finalized homegrown customizations, batch integrations, especially with systems originating from acquired companies, and overlapping software platforms that compete for the same functional areas.
The idea that some grand engine could just be plugged in is delusional, considering the present state of software technologies. Bringing together all the systems that operate the supply chain is a substantial undertaking entirely dependent on human engineering efforts.
The analysis of collective expenses indicates that data wrangling represents at least three quarters of the overall technical effort associated with a supply chain initiative. In contrast, crafting the smart aspects of the numerical recipe, such as forecasting and optimization, accounts for no more than a few percent of the overall efforts. Thus, the availability of a packaged, grand engine is largely inconsequential in terms of cost or delays. It would require built-in human-level intelligence for this engine to automatically integrate into the often haphazard IT landscape commonly found in supply chains.
Furthermore, any grand engine makes this undertaking even more challenging due to its existence. Instead of dealing with one complex system, the applicative landscape, we now have two complex systems: the applicative landscape and the grand engine. The complexity of integrating these two systems is not the sum of their respective complexities, but rather the product of those complexities.
The impact of this complexity on engineering cost is highly non-linear, a point that has already been made in the first chapter of this series of lectures. The first major bottleneck for supply chain optimization is the setup of the numerical recipe, which requires a dedicated engineering effort. This bottleneck largely eliminates the benefits that could be conceivably associated with any kind of packaged grand supply chain engine.

While the setup requires a substantial engineering effort, it might be a one-time investment, akin to paying an entry ticket. Unfortunately, supply chains are living entities under constant evolution. The day a supply chain stops changing is the day the company goes bankrupt. Changes are both internal and external.
Internally, the applicative landscape is constantly changing. Companies cannot freeze their applicative landscape even if they wanted to, as many upgrades are mandated by enterprise software vendors. Ignoring these mandates would relieve the vendors from their contractual obligations, which is not an acceptable outcome. Beyond purely technical updates, any sizable supply chain is bound to phase in and phase out software pieces as the company itself changes.
Externally, markets are continuously changing as well. New competitors, sales channels, and potential suppliers emerge all the time, while some disappear. Regulations keep changing. While algorithms may automatically capture some of the straightforward changes, like demand growth for a class of products, we do not yet have algorithms to cope with market changes in kind, rather than just in magnitude. The very problems that supply chain optimization tries to address are themselves changing.
If the software responsible for optimizing the supply chain fails to deal with these changes, employees fall back on spreadsheets. Spreadsheets may be crude, but at least employees can keep them relevant to the task at hand. Anecdotally, the vast majority of supply chains still operate under spreadsheets at the decision-making level, not at the transactional level. This is the living proof that software maintenance has failed.
Since the 1980s, enterprise software vendors have been delivering software products to automate supply chain decisions. Most companies operating large supply chains have already deployed several of these solutions over the last few decades. However, employees invariably revert to their spreadsheets, proving that even if the setup was originally deemed a success, something went wrong with the maintenance.
Maintenance is the second major bottleneck of supply chain optimization. The recipe requires active maintenance, even if the execution can be largely left unattended.

At this point, we have shown that supply chain optimization requires not only initial software engineering resources but ongoing software engineering resources as well. As previously pointed out in this series of lectures, nothing short of programmatic capabilities can realistically approach the diversity of problems faced by real-world supply chains. Spreadsheets do count as programmable tools, and their expressiveness, as opposed to buttons and menus, is what makes them so attractive to supply chain practitioners.
As software engineering resources have to be secured in most companies, it feels natural to call upon the IT department. Unfortunately, the supply chain is not the only department with this line of thinking. Every single department, including sales, marketing, and finance, ends up realizing that automating their respective decision-making processes requires software engineering resources. Furthermore, they must also deal with the transaction layer and all its underlying infrastructure.
As a result, most companies operating large supply chains nowadays have their IT departments buried under years of backlog. Thus, expecting the IT department to allocate further ongoing resources to the supply chain only makes the backlog worse. The option of allocating more resources to the IT department has already been explored, and it is usually no longer viable. These companies are already facing severe diseconomies of scale when it comes to the IT department. The IT backlog represents the third great bottleneck for supply chain optimization.
Ongoing engineering resources are needed, but the bulk of those resources cannot come from IT. Some support from IT can be envisioned, but it has to be a low-key affair.
These three great bottlenecks define why a specific role is needed: the supply chain scientist is the name we are giving to those ongoing software engineering resources needed to automate the supply chain’s mundane decisions and demanding decision-making processes.

Let’s proceed with a more precise definition based on Lokad’s practice. The mission of the supply chain scientist is to craft numerical recipes that generate the mundane decisions needed daily to operate the supply chain. The scientist’s work starts with the database extracts collected from all over the applicative landscape. The scientist is expected to code the recipe that crunches those database extracts and bring those recipes to production. The scientist takes full responsibility for the quality of the decisions generated by the recipe. The decisions aren’t generated by some sort of ambient system; they are the direct expression of the scientist’s insights conveyed through a recipe.
This single aspect is a critical departure from what is usually understood as the role of a data scientist. However, the mission doesn’t stop there. The supply chain scientist is expected to be able to present evidence supporting every single decision generated by the recipe. It is not some sort of opaque system that is responsible for the decisions; it’s the person, the scientist. The scientist should be able to meet with the lead of the supply chain or even with the CEO and provide a convincing rationale for any decision that has been generated by the recipe.
If the scientist isn’t in a position to potentially do a lot of damage to the company, then something is wrong. I’m not advocating granting anyone, and certainly not the scientist, large powers without supervision or accountability. I am merely pointing out the obvious: if you don’t have the power to negatively impact your company, no matter how poorly you perform, you don’t have the power to positively impact your company, no matter how well you perform either.
Large companies are unfortunately risk-averse by nature. Thus, it is very tempting to replace the scientist with an analyst. Contrary to the scientist in charge of the decisions themselves, the analyst is only responsible for shedding some light here and there. The analyst is mostly harmless and can’t do much beyond wasting their own time and some computing resources. However, being harmless is not what the role of the supply chain scientist is about.

Let’s discuss the term “supply chain scientist” for a second. This terminology is unfortunately imperfect. I originally coined this expression as a variation of “data scientist” about a decade ago, with the idea of branding this role as a variation of data scientist but with a strong supply chain specialization. The insight about specialization was correct, but the one about data science was not. I will be revisiting this point at the end of the lecture.
A “supply chain engineer” might have been a better wording, as it emphasizes a desire to master and control the domain, as opposed to pure understanding. However, engineers, as commonly understood, are not expected to be on the forefront of the action. The proper term would probably have been supply chain quant, as in quantitative supply chain practitioners.
In finance, a quant or quantitative trader is a specialist who leverages algorithms and quantitative methods to make trading decisions. Quants can make a bank vastly profitable or conversely, vastly unprofitable. Human intelligence is magnified through machines, both the good and the bad.
In any case, it will be up to the community at large to decide on the proper terminology: analyst, scientist, engineer, operative, or quant. For the sake of consistency, I will keep using the term scientist in the rest of this lecture.

The primary deliverable for the scientist is a piece of software, more precisely, the numerical recipe responsible for generating daily supply chain decisions of interest. This recipe is a collection of all the scripts involved from the earliest stages of data preparation to the final stages of corporate validation of the decisions themselves. This recipe must be production-grade, meaning it can run unattended and that the decisions it generates are trusted by default. Naturally, this trust had to be earned in the first place, and ongoing supervision must ensure that this level of trust remains warranted over time.
Delivering a production-grade recipe is fundamental in order to turn the supply chain practice into a productive asset. This angle has already been discussed in the previous lecture on product-oriented delivery.
Beyond this recipe, there are numerous secondary deliverables. Some of them are also software, even if they don’t directly contribute to the generation of the decisions. This includes, for example, all the instrumentation that the scientist needs to introduce in order to craft and later maintain the recipe itself. Some other items are intended for colleagues within the company, including all the documentation of the initiative itself and of the recipe.
The source code of the recipe answers the “how” – how is it done? However, the source code does not answer the “why” – why is it done? The “why” must be documented. Frequently, the correctness of the recipe hinges on some subtle understanding of the intent. The delivered documentation must facilitate as much as possible the graceful transition from one scientist to the next, even if the former scientist isn’t available to support the process.
At Lokad, our standard procedure consists of producing and maintaining a grand book of the initiative, referred to as the Joint Procedure Manual (JPM). This manual is not only a complete operating manual of the recipe but also a collection of all the strategic insights that underlie the modeling choices made by the scientists.
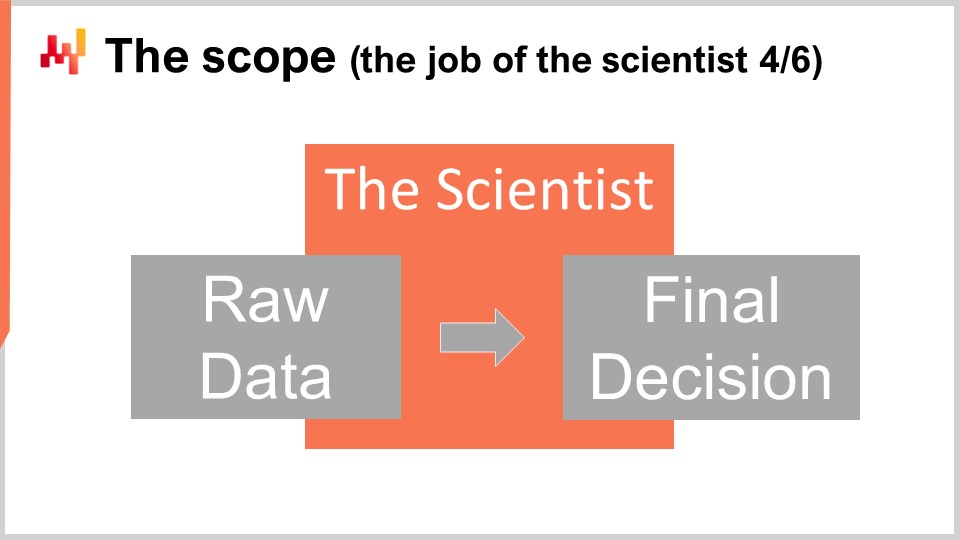
At the technical level, the work of the scientist starts from the point of extraction of the raw data and ends with the generation of the finalized supply chain decisions. The scientist must operate from raw data as extracted from the existing business systems. As each business system stands to have its own technological stack, the extraction itself is usually best dedicated to IT specialists. It is not reasonable to expect the scientist to become proficient with half a dozen SQL dialects or half a dozen API technologies merely to gain access to the business data. On the other hand, nothing should be expected from IT specialists except raw data extracts, neither data transformation nor data preparation. The extracted data made accessible to the scientist must be as close as possible to the data as it presents itself within the business systems.
At the other end of the pipeline, the recipe crafted by the scientist must generate the finalized decisions. The elements associated with the rollout of the decisions are not under the purview of the scientist. They are important but are also largely independent of the decision itself. For example, when considering purchase orders, establishing the final quantities falls within the scope of the scientist, but generating the PDF file – the order document expected by the supplier – does not. Despite these limits, the scope is somewhat large. As a result, it is tempting but misguided to fragment the scope into a series of subscopes. In larger companies, this temptation becomes very strong and must be resisted. Fragmenting the scope is the surest way to create numerous problems.
Upstream, if someone attempts to help the scientists by massaging the input, this attempt invariably ends up in “garbage in, garbage out” problems. Business systems are complex enough; transforming the data beforehand does nothing but add an extra accidental layer of complexity. Midstream, if someone attempts to help the scientists by taking care of a challenging piece of the recipe, like forecasting, then the scientists end up facing a black box in the middle of their own recipe. Such a black box undermines the white-boxing efforts of the scientists. And downstream, if someone attempts to help the scientist by re-optimizing the decisions further, this attempt inevitably creates confusion, and the two-layered optimization logics may even work at cross purposes.
This does not imply that the scientist has to work alone. A team of scientists can be formed, but the scope remains. If a team is formed, there must be a collective ownership of the recipe. This implies, for example, that if a defect in the recipe is identified, any member of the team should be able to step in and fix it.

Lokad’s experience indicates that a healthy mix for a supply chain scientist involves spending 40% of their time coding, 30% dialoguing with the rest of the company, and 30% writing documents, training materials, and exchanging with fellow supply chain practitioners or fellow supply chain scientists.
Coding is obviously needed to implement the recipe itself. However, once the recipe is in production, most of the coding efforts are directed not at the recipe itself but rather at its instrumentation. To improve the recipe, the scientist needs further insights, and in turn, those insights require dedicated instrumentation that must be implemented.
Dialoguing with the rest of the company is fundamental. Unlike S&OP, the purpose of these discussions is not to steer the forecast upward or downward. It’s about making sure that the modeling choices embedded in the recipe still faithfully reflect both the company’s strategy and all its operational constraints.
Finally, nurturing the institutional knowledge that the company has about supply chain optimization, either through direct training of the scientists themselves or the production of documents intended for colleagues, is critical. The performance of the recipe is, to a large extent, a reflection of the competency of the scientist. Having access to peers and seeking feedback is unsurprisingly one of the most efficient means to improve the competency of the scientists.

The biggest difference between a supply chain scientist, as envisioned by Lokad, and a mainstream data scientist is the personal commitment to real-world results. It may seem like a small, inconsequential thing, but experience says otherwise. A decade ago, Lokad learned the hard way that commitment to the delivery of a production-grade recipe was not a given. On the contrary, the default attitude of people trained as data scientists appears to be treating production as a secondary concern. The mainstream data scientist expects to manage the smart bits, like machine learning and mathematical optimization, while dealing with all the random trivia that comes with the real-world supply chain is too frequently perceived as beneath them.
Yet, the commitment to a production-grade recipe implies dealing with the most random things. For example, in July 2021, many European countries suffered catastrophic floods. A client of Lokad based in Germany had half of its warehouses flooded. The supply chain scientist in charge of this account had to re-engineer the recipe almost overnight to make the most of this severely degraded situation. The fix wasn’t some sort of grand machine learning algorithm, but rather a set of decoded heuristics. Conversely, if the supply chain scientist does not own the decision, then this person won’t be able to craft a production-grade recipe. It is a matter of psychology. Delivering a production-grade recipe requires immense intellectual effort, and the stakes have to be real in order to achieve the necessary level of focus from an employee.
Having clarified the job of a supply chain scientist, let’s discuss how it works from a human resources perspective. First, among corporate concerns, the scientist must report to the head of the supply chain or at least to someone who qualifies as senior supply chain leadership. It does not matter if the scientist is internal or external, as is often the case with Lokad. The point remains that the scientist must be under the direct supervision of someone who wields the power of a supply chain executive.
One common mistake is to have the scientist report to the head of IT or the head of data analytics. As crafting a recipe is a coding exercise, the supply chain leadership might not feel fully comfortable supervising such an undertaking. However, this is incorrect. The scientist needs supervision from someone who can approve whether the generated decisions are acceptable or not, or who can at least make this approval happen. Putting the scientist anywhere but under the direct supervision of the supply chain leadership is a recipe for endlessly operating through prototypes that never make their way to production. In this situation, the role inevitably reverts to that of an analyst, and the initial ambitions of the quantitative supply chain initiative are abandoned.

The very best supply chain scientists generate outsized returns compared to average ones. This has been Lokad’s experience and mirrors the pattern identified decades ago in the software industry. Software companies have long observed that the very best software engineers have at least 10 times more productivity than average ones, and mediocre engineers can even have negative productivity, making the software worse for every hour spent on the codebase.
In the case of supply chain scientists, superior competency not only improves productivity but, more importantly, it improves the end-game supply chain performance. Given the same software tools and mathematical instruments, two scientists do not achieve the same outcome. Thus, hiring someone with the potential to become one of the best scientists is of primary importance.
Lokad’s experience, based on hiring 50+ scientists, indicates that unspecialized engineering profiles are usually quite good. While counterintuitive, people with formal training in data science, statistics, or computer science are typically not the best fit for supply chain scientist positions. These individuals too frequently overcomplicate the recipe and don’t pay nearly enough attention to the mundane but critical aspects of the supply chain. The ability to pay attention to a multitude of details and the ability to persevere endlessly while chasing fringe numerical artifacts seem to be the leading qualities of the best scientists.
Anecdotally, at Lokad, there has been a good track record with young engineers who have spent a few years as auditors. In addition to familiarity with corporate finance, it seems that talented auditors develop a capacity to wade through an ocean of corporate records, which aligns with the day-to-day reality of a supply chain scientist.

While hiring ensures that recruits have the right potential, the next step is to ensure they are properly trained. Lokad’s default position is that they don’t expect people to know anything about supply chain beforehand. Being knowledgeable about supply chain is a plus, but academia remains somewhat deficient in this regard. Most supply chain degrees focus on management and leadership, but for young graduates, it’s essential to have proper foundational knowledge in topics like those covered in the second, third, or fourth chapters of this series of lectures. Unfortunately, this is often not the case, and the quantitative parts of these degrees can be underwhelming. As a result, supply chain scientists must be trained by their employers. This series of lectures reflects the type of training materials used at Lokad.

Performance reviews for supply chain scientists are important for a variety of reasons, such as ensuring that the company’s money is well spent and determining promotions. The usual criteria apply: attitude, diligence, proficiency, etc. However, there is a counterintuitive aspect: the best scientists achieve results that make supply chain challenges appear almost invisible, with minimal drama.

Training a scientist to maintain existing recipes while retaining the previous level of supply chain performance takes about six months, while training a scientist to implement a prediction-grade recipe from scratch takes about two years. Talent retention is critical, especially since hiring experienced supply chain scientists is not yet an option.
In many countries, the median tenure for engineers under 30 in software and adjacent fields is quite low. Lokad achieves a higher median tenure by focusing on employee well-being. Companies cannot bring happiness to their employees, but they can avoid making their employees miserable through inane processes. Sanity goes a long way in employee retention.

A competent, experienced supply chain scientist cannot be expected to take over an existing recipe quickly, as the recipe reflects the unique strategy of the company and the quirks of the supply chain. Transitioning from one supply chain to another can take about a month in the best conditions. It is not reasonable for a sizable company to depend on a single scientist; Lokad ensures that two scientists are proficient with any recipe used in production at any given time. Continuity is essential, and one way to achieve this is through a manual jointly created with clients, which can facilitate unplanned transitions between scientists.

The supply chain scientist’s role requires an unusual level of cooperation with multiple departments, especially IT. The proper execution of the recipe depends on the data extraction pipeline, which is the responsibility of IT.
There is a relatively intense phase of interaction between IT and the scientist at the beginning of the first quantitative supply chain initiative, which lasts for about two to three months. Afterward, once the data extraction pipeline is in place, the interaction becomes less frequent. This dialogue ensures that the scientist remains aware of the IT roadmap and any software upgrades or changes that may impact the supply chain.
In the initial phase of a quantitative supply chain initiative, there is a relatively intense interaction between IT and the scientists. During the first two or three months, the scientist needs to interact with IT several times per week. Afterward, once the data extraction pipeline is in place, interaction becomes much less frequent, about once per month or less. Besides solving the occasional glitch in the pipeline, this dialogue ensures that the scientist remains aware of the IT roadmap. Any software upgrade or replacement may require days or even weeks of work for the scientist. To avoid downtime, the recipe must be modified to accommodate changes in the applicative landscape.

The recipe, as implemented by the scientist, optimizes dollars or euros of returns. We covered this aspect in the very first lectures of this series. However, the scientist should not be expected to decide how to model costs and profits. While they should propose models to reflect the economic drivers, it’s ultimately the role of finance to decide whether those drivers are deemed correct or not. Many supply chain practices evade the problem by focusing on percentages, such as service levels and forecast accuracies. However, these percentages have almost no correlation with the financial health of the company. Thus, the scientist must routinely engage with finance and have them challenge the modeling choices and assumptions made in the numerical recipe.
Financial modeling choices are transient, as they reflect the changing strategy of the company. The scientist is also expected to craft some instrumentation attached to the recipe for the finance department, such as the maximal projected amount of working capital associated with inventory for the upcoming year. For a mid-size or large company, it’s reasonable to have a quarterly review by a finance executive of the work done by the supply chain scientist.

One of the biggest threats to the validity of the recipe is accidentally betraying the strategic intent of the company. Too many supply chain practices evade strategy by hiding behind percentages used as performance indicators. Inflating or deflating the forecast through sales and operations planning (S&OP) is not a substitute for clarifying strategic intent. The scientist isn’t in charge of company strategy, but the recipe will be incorrect if they don’t understand it. Alignment of the recipe with the strategy must be engineered.
The most direct way to assess whether the scientist understands the strategy is to have them re-explain it to leadership. This allows for misunderstandings to be caught more easily. In theory, this understanding is already documented by the scientist in the initiative manual. However, experience indicates that executives rarely have the time to review operational documentation in detail. A simple conversation expedites the process for both parties.
This meeting is not intended for the scientist to explain everything about supply chain models or financial results. The sole purpose is to ensure a proper understanding of the person holding the digital pen. Even in a large company, it’s reasonable for the scientist to meet with the CEO or relevant executive at least once a year. The benefits of a recipe more in tune with leadership intent are vast and often underestimated.

Supply chain improvements are part of ongoing digital modernization. This requires some reorganization of the company itself. Although changes may not be drastic, weeding out obsolete practices is an uphill battle. When executed correctly, a supply chain scientist’s productivity is significantly higher than that of a traditional planner. It’s not uncommon for a single scientist to be responsible for more than half a billion dollars or euros worth of inventory.
A drastic reduction of the supply chain headcount is possible. Some client companies of Lokad, who were historically under immense competitive pressure, took this approach and survived in part due to those savings. Most of our clients, however, are opting for a more gradual reduction of the headcount as planners naturally move on to other positions.
The planners who remain reorient their efforts towards customers and suppliers. The feedback that they collect proves very useful to the supply chain scientists. Indeed, the work of the scientist is inward-looking by nature. They operate over the company’s data, and it is difficult to see what is simply absent.
Many business voices have been advocating for a long time to forge stronger ties with both customers and suppliers. However, it is easier said than done, especially if efforts are routinely neutralized due to ongoing firefighting, reassuring customers, and pressuring suppliers. The supply chain scientists can provide much-needed relief on both fronts.

S&OP (Sales and Operations Planning) is a widespread practice intended to foster company-wide alignment through a shared demand forecast. However, no matter what the original ambitions may have been, the S&OP processes that I’ve ever witnessed were best characterized by an endless series of unproductive meetings. Except for ERP implementations and compliance, I can’t think of any corporate practice as soul-damaging as S&OP. The Soviet Union may have disappeared, but the spirit of the Gosplan lives on through S&OP.
An in-depth critique of S&OP would deserve a lecture of its own. However, for the sake of brevity, I will simply say that a supply chain scientist is a superior alternative to S&OP in every dimension that matters. Unlike S&OP, the supply chain scientist is grounded in real-world decisions. The only thing that prevents a scientist from being one more agent of a bloated corporate bureaucracy is not their character or competency; it’s having skin in the game through those real-world decisions.
Planners, inventory managers, and production managers are frequently big consumers of all sorts of business reports. Those reports are usually produced by enterprise software products commonly referred to as business intelligence tools. The typical supply chain practice consists of exporting a series of reports into spreadsheets and then using a collection of spreadsheet formulas to blend all this information to semi-manually generate the decisions of interest. Yet, as we have seen, the recipe of the scientist replaces this combination of business intelligence and spreadsheets.
Furthermore, neither business intelligence nor spreadsheets are suitable to support the implementation of a recipe. Business intelligence lacks expressiveness, as the relevant calculations cannot be expressed through this class of tools. Spreadsheets lack maintainability and sometimes scalability, but mostly maintainability. The design of spreadsheets is largely incompatible with any kind of correctness by design, which is very much needed for supply chain purposes.
In practice, the instrumentation of a recipe as implemented by the scientist does include numerous business reports. Those reports replace the ones that were generated so far through business intelligence. This evolution doesn’t necessarily imply the end of business intelligence, as other departments may still benefit from this class of tools. However, as far as the supply chain is concerned, the introduction of the supply chain scientist heralds the end of the business intelligence era.

If we put aside a few tech giants who can afford to throw hundreds, if not thousands, of engineers at every software problem, the typical outcome of data science teams in regular companies is dismal. Usually, nothing of substance ever gets accomplished by those teams. However, data science, as a corporate practice, is only the latest iteration of a series of corporate fads.
In the 1970s, operational research was all the rage. In the 1980s, rule engines and knowledge experts were popular. At the turn of the century, data mining and data miners were sought after. Since the 2010s, data science and data scientists have been considered the next big thing. All these corporate trends follow the same pattern: a genuine software innovation occurs, people get overly enthusiastic about it, and they decide to forcibly embed this innovation into the company through the creation of a new dedicated department. This is because it’s always much easier to add divisions to an organization as opposed to modifying or removing existing ones.
However, data science as a corporate practice fails because it is not firmly rooted in action. This makes all the difference between a supply chain scientist, who is committed from day one to be responsible for generating real-world decisions, and the IT department.

If we can put aside egos and fiefdoms, the supply chain scientist represents a much better deal than the former status quo. The typical IT department is buried under years of backlog, and pursuing more resources is not a reasonable proposition, as it backfires by inflating expectations of other departments and further increasing the backlog.
On the contrary, the supply chain scientist paves the way to a decrease in expectations. The scientist only expects raw data extracts to be made available, and their crunching battles are their responsibility. They expect nothing from the IT department in this regard. The supply chain scientist should not be seen as a corporate-sanctioned version of shadow IT. It’s about making the supply chain department responsible and accountable for its own core competency. The IT department manages the low-level infrastructure and the transactional layer, while the supply chain decision layer should be entirely up to the supply chain department.
The IT department must be an enabler, not a decision-maker, except for the truly IT-centric parts of the business. Many IT departments are aware of their backlog and embrace this new deal. However, if the instinct to protect what is perceived as their territory is too strong, they may refuse to let go of the supply chain decision layer. These situations are painful and can only be resolved through the direct intervention of the CEO.

From afar, our conclusion might be that the role of the supply chain scientist can be seen as a more specialized variation of the data scientist. Historically, this was how Lokad attempted to fix issues associated with the corporate practice of data science. However, we realized a decade ago that this was insufficient. It took us years to gradually uncover all the elements that have been presented today.
The supply chain scientist is not an add-on to the company’s supply chain; it’s a clarification on the ownership of the mundane daily supply chain decisions. To get the most out of this approach, the supply chain, or at least its planning component, must be remodeled. Adjacent departments like finance and operations must also accommodate some change, although to a much lesser degree.
Nurturing a team of supply chain scientists is a sizable commitment for a company, but when done properly, productivity is high. In practice, each scientist ends up replacing 10 to 100 planners, forecasters, or inventory managers, netting huge payroll savings even if the scientists command higher salaries. The supply chain scientist illustrates a new deal with IT, repositioning IT as an enabler rather than a solution provider, removing many, if not most, IT-related bottlenecks.
More generally, this approach can be mirrored in all other non-IT departments of the company, such as marketing, sales, and finance. Each department has its own mundane daily decisions to address, which would also extensively benefit from the same sort of automation. However, just like the supply chain scientist is first and foremost an expert in supply chain
However, just like a supply chain scientist is first and foremost an expert in supply chain, a marketing scientist or marketing quant should be an expert in marketing. The perspective of the scientist paves the way to make the most of the combination of machine and human intelligence in this early 21st century.
The next lecture will be on the 10th of May, a Wednesday, at the same time of the day, 3 pm Paris time. Today’s lecture was non-technical, but the next one will be largely technical. I will be presenting techniques for pricing optimization. Mainstream supply chain textbooks typically do not feature pricing as an element of supply chain; however, pricing does substantially contribute to the balance of supply and demand. Also, pricing tends to be highly domain-specific, as it is all too easy to incorrectly approach the challenge altogether when thinking in abstract terms. Thus, we will narrow our investigations to the automotive aftermarket. This will be the occasion to revisit the elements brought forward with Stuttgart, one of the supply chain personas I introduced in the third chapter of this series of lectures.

And now, I will be proceeding with the questions.
Question: It took academia almost a decade to figure out that the data science field has emerged and that they should teach it at high school. Do you already see the same happening in supply chain academia circles with adopting the supply chain sciences perspective?
First, I’m not aware of data science being taught in high schools in France. They barely teach anything that is computer-related in high school at all, let alone data science. I’m not too sure where they would even find the professors or teachers to do that. But I can understand that you want high school students to have some digital proficiency. I believe that getting familiar with programming is a very good thing, and you can do it even earlier, from my own experience, starting from the age of seven or eight, depending on the child’s maturity. You can do it even in primary school, but we are talking about just basic programming concepts: variables, lists of instructions, and these sorts of things. I believe that data science largely exceeds the sorts of things that should be taught at high school, unless you have prodigies or something. It is, for me, clearly something that is for people at the university level, either undergraduate or graduate.
Indeed, it took academia a decade to put data science forward, but let’s pause for a moment. I described data science as a corporate practice, which is pretty much the mirror version of what academia does while teaching data science. So, we need to think about the problem, and here, I think one of the problems is that it is incredibly difficult to teach something that you don’t practice. At least at the university level, if not below that. What I see is that we have already a problem with data science, as people who are teaching data science are not the people who are actually doing data science in places that matter, like Microsoft, Google, Facebook, OpenAI, and whatnot.
For supply chain, we have a similar problem, and having access to people with the right experience is just incredibly difficult. I hope, and this is a shameless plug of mine, that Lokad will start, in the coming weeks, trying to provide some materials intended for supply chain degrees. We will start to push some materials that are packaged in a way that should make them appropriate for professors in academia, so they can roll out those insights. Obviously, they will have to use their own judgment to assess whether those materials that Lokad is pushing are actually worth being taught to students.
Question: Is Lokad’s domain-specific language not used elsewhere? Beyond Lokad, how do you motivate potential new hires to learn something that they will likely never use again in their next job?
That is exactly the point I was making about the problem I had with data scientists. People were literally applying, saying, “I want to do TensorFlow, I am a TensorFlow guy” or “I’m a PyTorch guy.” This is not the right attitude. If you confuse your identity with a set of technical tools, you’re missing the point. The challenge is understanding supply chain problems and how to quantitatively address them to generate production-grade decisions.
In this lecture, I mentioned it takes six months for a supply chain scientist to gain proficiency to maintain a recipe and two years to engineer a recipe from scratch. How much time does it take to be completely proficient with Envision, our proprietary programming language? In our experience, it takes three weeks. Envision is a small detail compared to the overall challenge, but it’s an important one. If your tooling is poor, you’ll face immense accidental problems. However, let’s be realistic: it’s a small piece of the overall puzzle.
People who spend time at Lokad learn immensely about supply chain problems. The programming language could be rewritten in other languages, but it might take more lines of code. What people, especially young engineers, often don’t realize is how transient many technologies are. They don’t last long, usually just a couple of years before they’re replaced by something else.
We’ve seen an endless series of technologies come and go. If a candidate says, “I really care about the technical details,” they’re probably not a good candidate. That was my problem with data scientists – they wanted the fancy, bleeding-edge stuff. Supply chains are immensely complex systems, and when you make a mistake, it can cost millions. You need production-grade tools, not the latest, untested package.
The best candidates have a genuine interest in becoming supply chain professionals. The important part is the supply chain, not the details of the programming language.
Question: I am pursuing a bachelor’s degree in supply chain, transportation, and logistics management. How can I become a supply chain scientist?
First, I encourage you to apply at Lokad. We have positions open all the time. But more seriously, the key to becoming a supply chain scientist is having an opportunity at a company that is willing to automate its supply chain decisions. The most important aspect is ownership of the decisions. If you can find a company that is willing to give this a try, it will go a long way in helping you become a scientist.
As you face the challenges of production-grade decision making, you’ll realize the importance of the topics I’m discussing in this series of lectures. When you’re dealing with predictions that will drive millions of dollars worth of inventory, orders, and stock movements, you’ll understand the immense responsibility and the need for correctness by design. I’m pretty sure that other companies will grow and acquire many more opportunities. But even in my wildest dreams, I don’t think I can hope that every single company on Earth will be leveraging Lokad. There will be plenty of companies that will always decide to do it their way, and they’ll be just fine.
Question: Since 40% of a supply chain scientist’s daily routine is coding, which programming language would you suggest for undergraduate students to learn first, particularly those studying management?
I would say that whatever is readily accessible. Python is a good start. My suggestion is to actually try several programming languages. What you expect from a supply chain engineer is pretty much the opposite of what you expect from software engineers. For software engineers, my default advice is to pick one language and go super deep, really understanding all the nuances. But for people who are ultimately generalists, I would say do the opposite. Try a little bit of SQL, a little bit of Python, a little bit of R. Pay attention to the syntax of Excel, and maybe have a look at languages like Rust, just to see how they look like. So, pick whatever you have accessible. By the way, Lokad has plans to make Envision readily accessible to students for free, so stay tuned.
Question: Do you see graph databases having a significant impact on supply chain predictions?
Absolutely not. Graph databases have been around for more than two decades, and while they are interesting, they are not as powerful as relational databases like PostgreSQL and MariaDB. For supply chain predictions, having graph-like operators is not what it takes. In forecasting competitions, none of the top 100 participants have been using a graph database. However, there are things that can be done with deep learning applied to graphs, which I will illustrate in my next lecture about pricing.
Regarding the question of whether supply chain scientists should be involved in the goal definition among customer data science projects, I believe there is a problem with the underlying assumption of focusing on data science before understanding the problem we are trying to solve. However, rephrasing the question, should supply chain scientists be involved in the goal definition of supply chain optimization? Yes, absolutely. Having the scientist uncovering what it is that we truly want is difficult, and it requires close collaboration with the stakeholders to ensure the right goals are pursued. So, should the scientists be on board for that? Absolutely, it is critical.
However, let’s clarify that this is not a data science initiative; it is a supply chain initiative that happens to be able to use data as a suitable ingredient. We really need to start from the supply chain problems and ambitions, and then, as we want to make the most of modern software, we need these scientists. They will help polish your understanding of the problem further because the line of demarcation between what is feasible in software and what remains strictly the domain of human intelligence is kind of fuzzy. You need the scientists to navigate this line of demarcation.
I hope to see you two months from now, on May 10th, for the next lecture, where we will be discussing pricing. See you then.