00:05 Introduction
02:50 Two delusions
09:09 A compiler pipeline
14:23 The story so far
18:49 Bill of landing
19:40 Language design
23:52 The future
30:35 The past
35:57 Choosing the battles
39:45 Grammars 1/3
42:41 Grammars 2/3
49:02 Grammars 3/3
53:02 Static analysis 1/2
58:50 Static analysis 2/2
01:04:55 Type system
01:11:59 Compiler internals
01:27:48 Runtime environment
01:33:57 Conclusion
01:36:33 Upcoming lecture and audience questions
Description
The majority of supply chains are still run through spreadsheets (i.e. Excel), while enterprise systems have been in place for one, two, sometimes three, decades - supposedly to replace them. Indeed, spreadsheets offer accessible programmatic expressiveness, while those systems generally do not. More generally, since the 1960s, there has been a constant co-development of the software industry as a whole and of its programming languages. There is evidence that the next stage of supply chain performance will be largely driven by the development and adoption of programming languages, or rather of programmable environments.
Full transcript

Welcome to this series of supply chain lectures. I’m Joannes Vermorel, and today I will be presenting “Languages and Compilers for Supply Chain.” I do not remember having ever seen compilers discussed in any supply chain textbook, and yet the topic is of primary importance. We have seen in the very first chapter of this series, in the lecture titled “Product-Oriented Delivery,” that programming is the key to capitalizing on the time invested by supply chain experts. Without programming, we can’t capitalize on their time, and we treat supply chain experts as expendable.
Furthermore, in this very fourth chapter, through the two previous lectures “Mathematical Optimization for Supply Chain” and “Machine Learning for Supply Chain,” we have seen that these two fields - optimization and learning - have become driven by programming paradigms during the course of the last decade, instead of remaining a set of algorithms and models as it used to be the case in the past. All of these elements point to the primary importance of programming languages, and thus it begs the question of a programming language and compiler engineered to address supply chain challenges.
The purpose of this lecture is to demystify the design of such a programming language intended for supply chain purposes. Your company is probably never going to engineer such a programming language of its own. Nevertheless, having some insight into the topic is fundamental in order to be able to assess the adequacy of the tooling that you have, and to assess the adequacy of the tooling that you intend to acquire in order to address the supply chain challenges faced by your company. Furthermore, this lecture should also help you avoid some of the big mistakes that people who have no insight whatsoever in this topic tend to make in this area.

Let’s start by dispelling two delusions that have been prevalent in enterprise software circles for the last three decades or so. The first is the “Lego programming” delusion, where programming is thought of as something that can be entirely bypassed. Indeed, programming is hard, and there are always vendors who will promise that through their product and fantastic technology, programming can be turned into a visual experience that is accessible to anybody, removing entirely all the difficulty of programming itself so that the experience essentially becomes akin to just assembling Lego, something that even a child can do.
This has been attempted countless times in the last couple of decades and has always invariably failed. At best, products that were intended to deliver a visual experience turned into regular programming languages that are not especially easier to master compared to other programming languages. This is, by the way, anecdotally the reason why, for example, in the series of Microsoft products, there are the “Visual” series, like Visual Basic for Application and Visual Studio. All those visual products were introduced in the 90s with the hope of turning programming into a purely visual experience with designers where it would be just drag-and-drop. The reality is that all those tools did ultimately achieve a very significant degree of success, but they are just fairly regular programming languages nowadays. There is very little left from the visual parts that were at the inception of those products.
The Lego approach failed because fundamentally, the bottleneck is not the hurdle of programming syntax. This is a hurdle, but it’s a minimal one, especially compared to mastering the concepts that are involved whenever you want to roll out any kind of sophisticated automation. Your mind becomes the bottleneck, and your understanding of the concepts that are at play is much more significant than the syntax.
The second delusion is the “Star Wars tech” delusion, which consists of thinking that it’s just easy to plug and play fantastic pieces of technology. This delusion is very appealing to vendors and in-house projects alike. Essentially, it becomes very tempting to say there is this fantastic NoSQL database we can just drop in, or there is this fantastic deep learning stack we can take in, or this graph database, or this distributed active framework, etc. The problem with this approach is that it’s treating technology as it’s treated in Star Wars. When you have a mechanical hand, the hero can just get the mechanical hand, and it works. But in reality, integration problems dominate.
Star Wars bypasses the fact that there would be a series of problems: first, you would need antibiotics, then a long re-education of the hand to even be able to use it. You would also need a maintenance program for the hand because it’s mechanical, and what about the power source, etc. All of these problems are just bypassed. You just plug in the fantastic piece of technology, and it works. This is not the case in reality. Integration problems dominate, and for example, in large software companies, most software engineers are not working on fantastically cool pieces of technology. The bulk of the engineering workforce of the vast majority of those large software vendors is dedicated just to the integration of all the parts.
When you have modules, components, or apps, you need a small army of engineers to just glue all those things together and cope with all the problems that emerge when you try to bring those things together. Even once you’ve passed all the hurdles of integration, you still need a lot of engineering workforce just to cope with the fact that when you modify any part of the system, you tend to create problems in other parts of the system. So you need this engineering workforce to chase around to fix those problems.
By the way, as an anecdote, one other problem that I’ve witnessed with cool pieces of tech is the Dunning-Kruger effect that it creates among engineers. You introduce a cool piece of tech in your stack, and suddenly engineers, just because they’ve started to toy with a piece of tech that they barely understand, think that they are suddenly AI experts or something. That’s a typical case of the Dunning-Kruger effect and is very strongly related to the number of cool tech pieces that you drop into your solution. In conclusion, with those two delusions, we see that we can’t really bypass the problem of programming. We have to address it functionally, including the difficult parts.
Now, having said that, the interesting thing about programming languages is that enterprise software vendors keep reinventing, accidentally, programming languages, and they do it all the time. Indeed, in supply chain, there is a ferocious need for configurability. As we have seen in previous lectures, the world of supply chain is diverse, and problems are numerous and varied. Thus, when you have a supply chain software product, there is an extremely intense need for configurability. Anecdotally, this is why configuring a piece of software is typically a multi-month and sometimes a multi-year project. It’s because there is a massive amount of complexity that goes into this configuration.
Configuration settings are often complex, not just buttons or checkboxes. You can have triggers, formulas, loops, and all sorts of blocks that go with that. It quickly goes out of control, and what you get through those configuration settings is an emergent programming language. However, since it’s an emergent programming language, it tends to be a very poor one.
Engineering an actual programming language is a well-established engineering task. There are dozens of books about the practicalities of engineering a production-grade compiler. A compiler is a program that converts instructions, typically text instructions, into machine code or a lower-level form of instructions. Whenever there is a programming language, there is a compiler involved. For example, inside an Excel spreadsheet, you have formulas, and Excel has a compiler of its own to compile those formulas and execute them. Most likely, the entire audience has been using compilers for their entire professional life without knowing it.
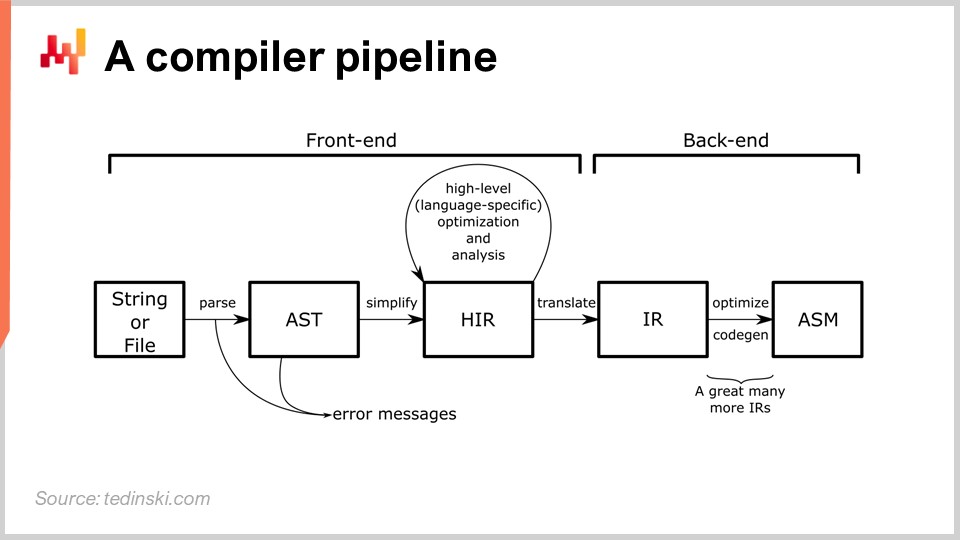
On the diagram, you can see a typical pipeline, and this archetype fits most programming languages you’ve probably ever heard of, such as Python, JavaScript, Java, and C#. All these languages have a pipeline essentially similar to the one outlined here. In a compiler pipeline, you have a series of transformations, and at every stage of the process, you have a representation that represents the entire program. The way a compiler is engineered is to have a series of well-identified transformations, and at every stage of the process, you’re working with the entire program. It’s just represented differently.
The idea is that every transformation is responsible for a well-specified set of problems. You address those problems and then move on to the next transformation that will address another aspect of the process. Typically, at every stage, you move closer to the machine-level code. The compiler starts with the script, and it begins with transformations that are very close to the syntax of the programming language of interest. During these early transformations, a typical compiler will capture syntactic mistakes that prevent the compiler from turning a script that does not even represent a valid program into something executable. We will be getting back to have a closer look at a compiler pipeline later on in this lecture.
This lecture is the fifth lecture of the fourth chapter of this series. In the first chapter, I presented my views about supply chain both as a field of study and as a practice. In the second chapter, I surveyed the methodologies appropriate for dealing with situations found in supply chain. As we have seen, most supply chain situations are fairly adversarial in nature, so we need strategies and methodologies that are resilient to adversarial behaviors from all parties within and outside the companies.
The third chapter is dedicated to supply chain personnel, and it is entirely dedicated to the study of the supply chain problems themselves. We need to be very careful not to entangle the problem we are uncovering with the sort of solution that we can imagine to address this problem. Those are two distinct concerns: we need to separate the problem from the solution.
The fourth and present chapter of this series of lectures is dedicated to the auxiliary sciences of supply chain. These auxiliary sciences are not supply chain per se, but they are very helpful to the practice of modern supply chain. We are currently moving through the ladder of abstractions. We started this chapter with the physics of computing, then with algorithms, we moved into the realm of software. We introduced mathematical optimization, which is of high interest for supply chain and also happens to be the foundation of machine learning.
Today, we are introducing languages and compilers, essential for implementing any kind of programming paradigm. While the topic of languages and compilers may come as a surprise to the audience, I believe that at this point, it should not be too much of a surprise. We have seen that mathematical optimization and machine learning should nowadays be approached through programming paradigms, which begs the question of how to implement those programming paradigms. That leads us to the design of a programming language and its supporting compiler, which is exactly the topic for today.

This is a summary of the rest of this lecture. We will start with high-level observations about the history and the market of programming languages. We will review industries that represent, I believe, both the future and the past of supply chain. Then we will gradually delve into the design of programming languages and compilers, moving forward with lower-level concerns and the technicalities involved in the design of a compiler.

Since the 1950s, thousands of programming languages have been brought to production. Estimates vary, but the number of programming languages that have been used for production purposes probably ranges between one thousand and ten thousand. Many of those languages are just variations or cousins from one another, sometimes even just the codebase of the compiler forked into a slightly different direction. It is notable that several very large enterprise software companies expanded quite a lot through the introduction of programming languages of their own making. For example, SAP introduced ABAP in 1983, Salesforce introduced Apex in 2006, and even Microsoft started out before Windows by engineering the Altair BASIC in 1975.
Historically, those of you in the audience old enough to remember the 90s might recall that vendors at the time were marketing third and fourth-generation programming languages. The reality is that there was a well-identified series of generations—first, second, third, fourth, etc.—leading to the fifth, where essentially the community stopped counting in terms of generations. During the first three or four decades, all those programming languages were following a nice progression toward higher levels of abstraction. However, by the end of the 90s, there were already many more directions besides having a higher degree of abstraction, depending on the use case.
Crafting a new programming language has been done many times. It’s a well-established field of engineering, and there are entire books dedicated to the subject from a very practical angle. The engineering of a new programming language is a practice that is much more grounded and predictable than, let’s say, carrying out a data science experiment. There is a near certainty that you will get the result you want if you’re doing the adequate engineering, considering what is known today and what is readily available as knowledge.
All of that really begs the question: what about a programming language specifically engineered for supply chain purposes? Indeed, there can be significant upside in terms of productivity, reliability, and even supply chain performance.

In order to address this question, we need to have a look at the future. Fortunately for us, the simplest way to look at the future is to examine one industry that has been consistently one decade ahead of everybody else for the last three decades or so, and that is the video gaming industry. This is a very large industry nowadays, and just to give you a sense of scale, the video game industry is now two-thirds of the aerospace industry worldwide in terms of comparative size, and it is growing much faster than aerospace. A decade from now, video games might actually be bigger than aerospace.
The interesting thing about the video game industry is that it has a very well-established structure. First, we have game engines, with the two leaders being Unity and Unreal. These game engines feature the low-level components that are of interest for super-intensive refined 3D graphics, and they lay out the landscape for the level of infrastructure of your code. There are a few companies that engineer very complex products called game engines, and these engines are used by the entire industry.
Next, we have game studios, which develop game code for every single game. The game code is going to be a codebase that is typically specific to the one game being developed. The game engine requires very hardcore software engineers that are very technically skilled but don’t necessarily know much about gaming. The development of game code is not as intensive in terms of pure raw technical skills. However, the software engineers who develop the game code need to understand the game they are working on. The game code establishes the platform for game mechanics, but it doesn’t specify the fine print.
This task is typically managed by game designers, who are not software engineers, but they write code in the scripting languages that are made available to them by the engineering team dealing with the game code. We have these three stages: game engines, which involve super technical hardcore software engineers creating core building blocks; studios, which have engineering teams, typically one per game, developing the game as a platform for game mechanics; and finally, game designers, who are not software engineers but are game specialists, implementing the behavior that will make the gamers, the clients at the end of the pipeline, happy.
Nowadays, the game code is frequently made accessible to the fanbase, meaning that game designers can write rules and potentially modify the game, but fans, who are just regular consumers of the games, can do that as well. There are some interesting anecdotes in the industry. For example, the game Dota 2, which is incredibly successful, began as a modification of an existing game. The first version, just named Dota, was a pure fanbase modification of the game World of Warcraft 3. You can see this degree of configurability and programmability at the level of game rules is very extensive because it was possible, from an existing commercial game, World of Warcraft 3, to create an entirely new game, which then became a massive commercial success of its own through the second version. Now, this is interesting, and we can start thinking, by looking at the gaming industry, what does it mean for the supply chain industry?
Well, we could think about what sort of parallel we could draw. We could have a supply chain engine that takes care of the very difficult algorithmic parts, the low-level infrastructure, and the core technological building blocks, such as mathematical optimization and machine learning. The idea is that, for every single supply chain, you would need an engineering team to bring all the relevant data and integrate the entire applicative landscape.
As a first stage, we would need the equivalent of game designers, who would be supply chain specialists. These specialists are not software engineers, but they are the people who will write, through simplified code, all the rules and mechanics needed to implement the predictive optimization of interest for the supply chain. The gaming industry provides a vivid example of what is likely to happen in the supply chain space in the coming decade.

So far, the gaming industry approach in supply chain remains science fiction, except for a few companies. I believe that most of those companies happen to be clients of Lokad. Back to the subject of today, we have seen in previous lectures that Excel remains the number one programming language in this industry. By the way, in terms of programming language, Excel is a functional reactive programming language, so it’s even its own class.
You might be hearing nowadays from vendors proposing to upgrade supply chains using some kind of data science setup. However, my casual observation over the last decade is that the vast majority of these initiatives have failed. This is already the past, and to understand why, we need to start looking at the list of programming languages involved. If we look at Excel, we see that it involves essentially two programming languages: Excel formulas and VBA. VBA is not even a requirement; you can go far with just VLOOKUPs in Excel. Typically, it’s going to be just one programming language, and it’s accessible to non-software engineers.
On the other hand, the list of programming languages required to replicate the capabilities of Excel with a data science setup is quite extensive. We will need SQL, and potentially several dialects of SQL, to access the data. We will need Python to implement the core logic. However, Python on its own tends to be slow, so you might need a sub-language like NumPy. At this point, you are still not doing anything in terms of machine learning or mathematical optimization, so for true hardcore numerical analysis, you will need something else, another programming language of its own, such as PyTorch, for example. Now that you have all these elements, you have quite a few moving parts already, so your configuration of the application itself will be quite complex. You will need a configuration, and this configuration will be written with yet another programming language, like JSON or XML. Arguably, these are not super complex programming languages, but it’s more to add to the plate.
What happens when you have so many moving parts is that you typically need a build system, something that can execute all the compilers and mundane recipes needed to produce the software. Build systems have languages of their own. The traditional approach is a language called Make, but there are many others. Additionally, since Excel is able to display results, you need a way to display things to the user and visualize stuff. This will be done with a mix of JavaScript, HTML, and CSS, adding more languages to the list.
At this point, we have a long list of programming languages, and an actual production setup could be even more complex. This explains why most companies that tried to go for this data science pipeline during the last decade have overwhelmingly failed and have just stayed with Excel in practice. The reason is that it involves mastering almost a dozen programming languages instead of just one, as in the case with Excel. We haven’t even started to touch any of the actual supply chain problems; we have just been discussing the technicalities in the way of actually starting to do anything.

Now, let’s start thinking about what a programming language for supply chain would look like. First, we have to decide what is inside the language and what belongs to the language as a first-class citizen and what belongs to libraries. Indeed, with programming languages, it is always possible to offload capabilities to libraries. For example, let’s look at the C programming language. It’s considered a fairly low-level programming language, and C does not have a garbage collector. However, it is feasible to use a third-party garbage collector as a library in a C program. Due to the fact that garbage collection is not a first-class citizen in the C programming language, the syntax tends to be relatively verbose and tedious.
For supply chain purposes, there are concerns like mathematical optimization and machine learning that are usually treated as libraries. So, we have a programming language, and all those concerns are essentially offloaded to third-party libraries. However, if we were to engineer a programming language for supply chain, it would really make sense to have those concerns engineered as essentially first-class citizens in the programming language itself. Also, it would make sense to have relational data as part of the language as a first-class citizen. In supply chain, the applicative landscape, which includes many pieces of enterprise software, has relational data in the form of relational databases, like SQL databases, all over the place. Pretty much all the enterprise software products that exist nowadays have at their core a relational database, which means that for supply chain purposes, as soon as we want to touch the data, the reality is that we will interact with data that is relational in nature. The data presents itself as a list of tables extracted from all those databases powering various apps, and each table has a list of columns or fields.
This really makes sense to have relational data within the language. Additionally, what about the user interface (UI) and user experience (UX)? One of the strong points of Excel is that all of that is completely embedded into the language, so you don’t have a programming language and then all sorts of third-party libraries to deal with presentation, rendering, and user interaction. All of that is part of the language. Having all of that made a first-class citizen would also be of very relevant interest as far as supply chain is concerned, at the very least if we want to be as good as Excel can be for supply chains.
Now, in language design, the grammar represents the formal representation of the rules that define a valid program according to your newly introduced programming language. Essentially, you start with a piece of text, and first, you will apply a lexer, which is a specific class of algorithms or a small program. The lexer decomposes your piece of text, the program that you’ve just written, into a sequence of tokens. The lexer isolates all the variables and symbols at play in your programming language. The grammar helps convert the sequence of tokens into the actual semantics of the program, defining what the program means and the exact, non-ambiguous set of operations that need to be made to execute it.
The grammar itself is typically approached as a trade-off between the concerns you want to internalize inside your language and the concepts you want to externalize. For example, if we approach relational data as an external concern, the programmer would need to introduce a lot of specialized data structures like dictionaries, lookups, and hash tables to perform manually inside the programming language all those operations. If the grammar wants to internalize the relational algebra, it means that the programmer can typically write all the relational logic directly in its relational form. However, that means that suddenly all those relational constraints and all this relational algebra become part of the burden that the grammar has to carry.
From a supply chain perspective, as relational data is super prevalent in enterprise software, it makes a lot of sense to have a grammar taking care of all the relational concerns directly at the grammar level in the language is important.

Grammars in computer science are an enormously studied subject. They have been around for decades, and yet, it’s probably the single area where enterprise software vendors fail the hardest. Indeed, they invariably end up conjuring accidental programming languages that emerge naturally whenever there are complex configuration settings at play. When you have conditions, triggers, loops, and responses, you typically need to take care of this language instead of letting it just emerge on its own.

What happens is that when you don’t have a grammar, whenever you bring changes to the application, you will end up with haphazard consequences on the actual behavior of the system. By the way, this also explains why upgrading from one version of a piece of enterprise software to another is usually very complex. The configuration is supposed to be the same, but when you actually try to run the same configuration in the next version of the software, you get completely different results. The root cause of these problems is the lack of grammar and established formalized semantics for what the configuration is going to mean.
The typical way to represent a grammar is formally using the Backus-Naur Form (BNF), which is a special notation. On the screen, what you can see is a mini programming language that represents US postal addresses. Each line with an equal sign represents a production rule. What you have on the left is a non-terminal symbol, and on the right of the equal sign is a sequence of terminal and non-terminal symbols. Terminal symbols are in red and represent symbols that cannot be derived any further. Non-terminal symbols are within brackets and can be derived further. This grammar here is not complete; there would be many more production rules to add for a complete grammar. I just wanted to keep this slide reasonably concise.
A grammar is something very straightforward to define in terms of syntax for your programming language, and it also ensures that it will be non-ambiguous. However, it’s not because it’s written with the Backus-Naur Form that it’s going to be a valid grammar or even a good grammar. To have a good grammar, we need to do a little more than that. The mathematical way to characterize a good grammar is to have a context-free grammar. A grammar is said to be context-free if the production rules can be applied for any non-terminal, irrespective of the symbols that you find on the right and on the left. The idea is that a context-free grammar is something where you can apply the production rules in any order, and as soon as you see a match or derivation, you just apply it.
What you get out of a context-free grammar is a grammar that, if you change something in it and this change creates an ambiguity, the compiler will not be able to compile the program where the ambiguity occurs. This is of primary interest when you intend to maintain a configuration for a long period of time. In supply chains, most enterprise software is very long-lived. It is not infrequent to see pieces of enterprise software operating for two or three decades. At Lokad, we are serving over 100+ companies, and it is fairly common that we extract data from systems that have been in place for over three decades, especially with large companies.
With a context-free grammar, you get the guarantee that if there is a change to be brought to this language (and remember, when I say “language,” I can mean something as basic as configuration settings), you will be able to identify the ambiguities that emerge when you apply this change. This is instead of having those ambiguities just happening without you realizing you have a problem, which can lead to difficulties when upgrading from one system to another.
What happens when people don’t know anything about grammars is that they manually write a parser. If you’ve never heard of a grammar, a software engineer would write a parser, which is a program that haphazardly creates a sort of tree that represents the parsed version of your program. The problem with that is you end up with a semantic for your program that is incredibly specific to the one version of the program that you have. So, if you change this program, you change the semantic, and you will get different results, which means you can have the same configuration but different behavior for your supply chain.
Fortunately, in 2004, there was a small breakthrough introduced by Brian Ford with a paper titled “Parsing Expression Grammars: A Recognition-Based Syntactic Foundation.” With this work, Ford provided the community with a way to formalize the sort of accidental ad-hoc parser that exists in the field. For example, these grammars are called Parsing Expression Grammars (PEGs), and with PEGs, you can convert those semi-accidental empirical parsers into actual formal grammars of some kind.
Python, for example, doesn’t have exactly a context-free grammar but has a PEG. PEGs are kind of fine if you have an extensive set of automated tests because, in this case, you can deal with the preservation of the semantic over time. Indeed, with PEGs, you have a formalization of your grammar, so you’re in a better situation compared to not having any grammar and just having a parser. However, in terms of evolution of the semantic, with a PEG, you will not automatically detect that you have a change of semantic if you change the grammar itself. Thus, you need to have an extensive suite of automated tests on top of your PEG, which, by the way, is exactly what the Python community has. They have a very robust and extensive set of automated tests. Now, from a supply chain perspective, I believe that grammars not only have an interest in making you realize their importance but also constitute a litmus test. You can actually test enterprise software vendors when discussing a piece of software with significant complexity. You should ask the vendor about the grammar they use for the complex configuration. If the vendor answers with “what’s a grammar?”, then you know that you’re in trouble, and maintenance will likely be slow and expensive.

Programming is very difficult, and people will get many things wrong. If it were easy, we wouldn’t even need programming in the first place. A good programming language minimizes the time it takes to identify an error and fix it. This is one of the most critical aspects of a programming language, ensuring decent productivity for whoever happens to be writing code.
Let’s consider the following situation: As you write code, if the error can be detected as you type, like a typo with a red underline in Microsoft Word, then the feedback loop to fix the error can be as short as 10 seconds, which is ideal. If the error can only be detected when you start running the program, the feedback loop will be at least 10 minutes long. In supply chain, we often have large datasets to process, and we can’t expect the program to start going through all the data in a matter of seconds. As a result, if the problem only happens at runtime, the feedback loop will be 10 minutes or more.
If the error can only be detected after the script completes, meaning the program has an error but doesn’t fail, the feedback loop will take around 10 hours or more. We went from 10 seconds of real-time feedback to 10 minutes if we have to run the program and then 10 hours if we have to inspect the numerical results and KPIs produced by the program.
There’s an even worse scenario: if the platform on which you operate is not strictly deterministic, meaning that with the same input and data, it can give you different results. This isn’t as strange as it may sound, as in supply chain, we might have things like Monte Carlo simulations going on. If there’s any randomness in the results, we can have something that fails only once in a while, and in this situation, the feedback loop is typically longer than 10 days. So, we went from 10 seconds to 10 days, and there are massive stakes in tightening this feedback loop. Static analysis represents a set of techniques that can be applied to detect problems, errors, or failures without even running the program in the first place. With static analysis, the idea is that you will not even run the program, which means that you can report the error in real time while people are typing, just like a red underline for typos in Microsoft Word. More generally, there is a strong interest in transforming every problem so that it moves up the ladder into an earlier class of feedback, changing issues that would take days to identify into minutes or minutes into seconds, and so on.
From a supply chain perspective, we have seen in one of the previous lectures that supply chains can expect a lot of chaos. We can’t have classical release cycles where you wait for the next version of your software to be delivered. Sometimes there are extraordinary events, like a tariff change, a container ship getting stuck in a canal, or a pandemic. These emergency situations call for emergency corrections, and the amount of static analysis that you can do over your programming language pretty much defines how much chaos you will get in production due to mistakes not captured in real time while typing the code. Extraordinary events may seem rare, but in practice, surprises in supply chain are quite common.

There are mathematical proofs that it’s not possible to detect all errors with a general programming language in a general situation. For example, it’s not even possible to prove that the program will complete, meaning that it’s not possible to guarantee that what you’ve written will not just keep running indefinitely.
With static analysis, you typically get three categories: some pieces of the code are probably good, some pieces are probably bad, and for many things in the middle, you just don’t know. The idea is that the more you displace from “don’t know” to “bad code”, the more effort you will need in terms of language design to convince the compiler that your program is valid. So, we have to strike a balance between how much effort you want to invest to convince the programming language that your code is correct versus how many guarantees you want to have on the program at compile time, even before the program actually runs. This is a matter of productivity.
Now, a quick list of typical errors detected with static analysis includes syntax errors, such as forgotten commas or parentheses. Some programming languages cannot even outline syntax errors before runtime, like Bash, the shell language on Linux. Static analysis can also detect type errors, which occur when you have the incorrect type or incorrect number of arguments for a function you’re calling.
Unreachable code can be detected as well, which means the code is fine, but it will never run because the entire program can execute without ever reaching that piece of code. It’s like dead code or a forgotten logic connection. Inconsequential code is another issue that can be identified, where the code executes but has no impact on the final output. It’s a variant of unreachable code.
Overspending code can also be detected, which refers to code that would run, except that the amount of computing resources needed vastly exceeds what you can afford for your program. A program consumes computing resources such as memory, storage, and CPU. Through static analysis, you can prove that a block of code consumes far more resources than you can afford, considering your constraints like having the calculation complete within a specific time frame. You’d want this to fail at compile time rather than run your program for an hour and then have it fail due to a timeout, which would lead to very low productivity.
However, there is a twist when it comes to static analysis. As you type, you’re dealing with a program that is invalid all the time. As you type keystroke by keystroke, you are transforming a valid program into an invalid one. An industry-grade solution for this situation is called a Language Server Protocol. This tooling comes with a programming language and is the state of the art when it comes to real-time error feedback for the programs you’re typing.
Through a Language Server Protocol, you can access features like “go to definition” when you click on a variable. The Language Server Protocol is fundamentally stateful, remembering the last version of your program that was correct, along with the available annotations and semantics. It preserves these annotations and extra tidbits when dealing with your broken program just because you’ve pressed an extra keystroke, and it’s not a valid program anymore. It’s a game changer in terms of productivity, and whenever there is any degree of urgency, it makes a big difference for supply chain purposes.

Now, let’s dig into the type system. As a first rough approximation, a type system is a set of rules that leverages categorization within the objects in your program, or the categorization of elements that you manipulate, to clarify whether certain interactions are allowed or disallowed. For example, typical types include strings, integers, and floating-point numbers, all of which are very basic types. It will define that adding two integers together is valid, but adding a string and an integer is not valid, except in JavaScript because the semantics are different there.
Type systems, in general, are an open research problem and can get incredibly abstract. To shed some light, we need to clarify that there are two kinds of types, which are frequently confused. First, there are the types of values, which only exist at runtime when the program is actually running. For example, in Python, if we are considering a function that returns the first element of an array of integers, then the type of the value returned by this function is going to be an integer. From this perspective, all programming languages have types – they are all typed.
Second, there are the types of variables, which only exist at compile time while the program is being compiled and not running yet. The challenge with variable types is extracting as much information as possible about those variables at compile time. If we go back to the previous example, in Python, it may or may not be possible to identify the type of the return value returned by the function, because Python is not entirely strongly typed at compile time.
From a supply chain perspective, we are looking for a type system that supports what we intend to do for the benefit of the supply chain. We want to be as restrictive as possible to capture problems and bugs early but also as flexible as possible to allow all the operations that could be of interest. For example, consider the addition of a date and an integer. In a regular programming language, you would probably say it’s not legitimate, but from a supply chain perspective, if we have a date and want to add seven days, it would make sense to write “date + 7”. There are many operations in supply chain planning that involve shifting dates by a certain number of days, so it would be useful to have an algebra where it’s okay to perform an addition between a date and a number.
In terms of types, do we want to allow adding one date to another? Probably not. However, do we want to allow the subtraction between two dates? Why not? If we subtract one date from another that occurs before it, we get the delta, which could be expressed in days. This makes a lot of sense for calculations involved in planning.
Continuing with the topic of dates, there are also characteristics that could be of interest when thinking about what a type system should do for us in terms of supply chain concerns. For example, what about restricting the acceptable time range? We could say that dates outside the scope of 20 years in the past and 20 years into the future are just not valid. Chances are that if we are doing a planning operation and at some point in the program we manipulate a date that is more than 20 years into the future, the odds are overwhelming that it’s not a valid planning scenario for most industries. You would not plan operations on a daily level more than 20 years ahead in most cases. So, we can not only take the usual types but redefine them in ways that are more restrictive and more appropriate for supply chain purposes.
Also, there is the whole uncertainty aspect. In supply chain management, we are always looking ahead, but unfortunately, the future is always uncertain. The mathematical way to embrace uncertainty is through random variables. It would make sense to have random variables incorporated into the language to represent uncertain future demand, lead times, and customer returns, among other things.
At Lokad, we have engineered Envision, a programming language dedicated to the predictive optimization of supply chains. Envision is a mix of SQL, Python, mathematical optimization, machine learning, and big data capabilities, all wrapped as first-class citizens within the language itself. This language comes with a web-based Integrated Development Environment (IDE), which means that you can write a script from the web and have all the modern code editing features. These scripts operate over an integrated distributed file system that comes with the Lokad environment, so the data layer is fully integrated into the programming language.
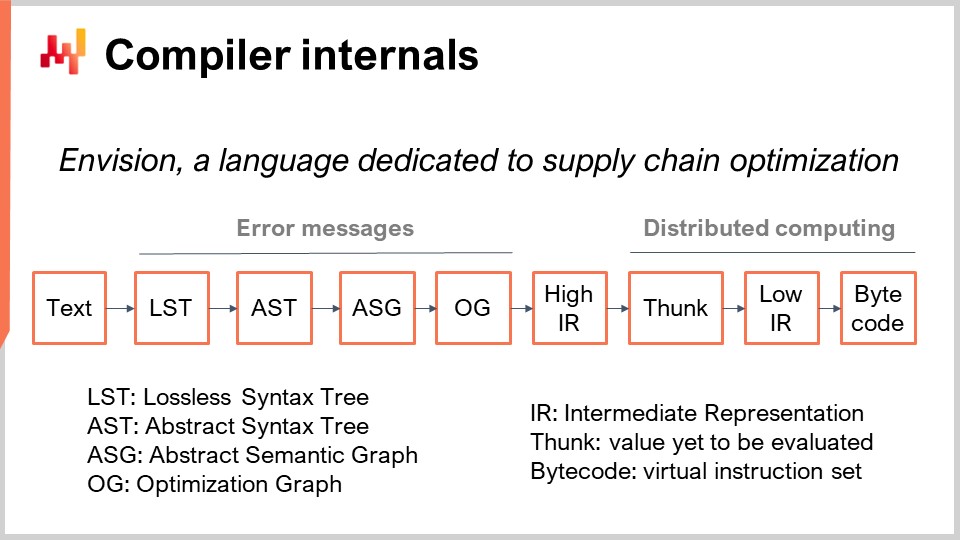
Envision scripts execute on a fleet of machines, designed to take advantage of an entire cloud. When the script is run, it will spread over many machines in order to run faster. On the screen, you can see the compiler pipeline used by Envision. Today, we are not going to discuss this programming language; we are just going to discuss its compiler pipeline because that’s the topic of interest for today’s lecture.
First, we start with a piece of text that contains the Envision script. It represents a program that has been written by a supply chain expert, not a software engineer, to address a specific supply chain challenge. This challenge could be deciding what to produce, what to replenish, what to move, or whether to adjust a price up or down. These use cases involve decisions about what to produce, replenish, move, or whether to adjust prices up or down. The script’s text contains the instructions, and the idea is to process this script and obtain the Lossless Syntax Tree (LST). The LST is of interest because it’s a very specific representation that does not discard any single character. Even non-significant whitespaces are preserved. The reason for this is to ensure that any automated rewrites of the program do not alter the existing code. This approach avoids situations where tools shuffle code, move indentations, or cause other disruptions that make the code difficult to recognize.
A basic refactoring operation, for example, might involve renaming a variable and all of its occurrences in the program without touching anything else. From the LST, we move to the Abstract Syntax Tree (AST), where we simplify the tree. Parentheses are not needed at this stage because the tree structure defines the priorities of all the operations. Additionally, we perform a series of desugaring operations to remove any syntax provided for the benefit of the end programmer.
Moving on from the AST to the Abstract Syntax Graph (ASG), we flatten the tree. This process involves decomposing complex statements with highly nested expressions into a sequence of elementary statements. For example, a statement such as “a = b + c + d” would be split into two statements, each with only one addition. This is precisely what happens during the transition from the AST to the ASG.
From the ASG, we move to the Optimization Graph (OG), where we perform type shaping and broadcasting, particularly in relation to relational algebra. As mentioned earlier, Envision embeds a relational algebra within the language. As hinted many times before, Envision embeds a relational algebra, like in relational databases or SQL databases, as a first-class citizen. There are numerous relational operations, and we check that these relational operations are valid according to the schema of the tables we are operating with when transitioning from ASG to OG. The Optimization Graph (OG) represents the last step of our compiler front-end and consists of pure, elementary relational operations that apply to the program, representing tiny bits of logic. Like in SQL, these elements are relational in nature.
The optimization graph is called “optimization” because there are numerous transformations that happen from OG to OG. These transformations occur because, when dealing with relational algebra, organizing operations in certain ways can make the program run much faster. For example, in SQL, if you have a filter and then an operation, or an operation first and then a filter, it is much better to first filter the data and then apply the operation. This ensures that operations are only applied to the necessary data, improving efficiency.
At Lokad, the last step of the front-end compiler is the High Intermediate Representation (HIR). The HIR is a clean, stable, and documented boundary between the front-end and the back-end of the compiler pipeline. Unlike the Optimization Graph (OG), which is constantly changing due to heuristics, the HIR is stable and provides a consistent input for the back-end of the compiler. Additionally, the HIR is serializable, meaning it can easily be transformed into a pack of bytes to be moved from one machine to another. This property is essential for distributing calculations across multiple machines.
From the High Intermediate Representation, we move on to “funcs”. Funcs are values that have yet to be evaluated and represent the atomic blocks of calculation within a distributed execution. For example, when adding two gigantic vectors from a table with billions of lines, there will be a series of funcs representing various portions of these vectors. Each funcs is responsible for adding a portion of the two vectors and is executed on one machine. Big calculations are split into many funcs to spread the workload over multiple CPUs and multiple machines if the calculation is sufficiently large to warrant this degree of distribution. Funcs are called “lazy” because they are not evaluated at first; they are evaluated when needed. Many calculations can happen before some funcs are actually computed, and once a func is computed, the func itself is replaced by its result.
Inside the func, you will find the low intermediate representation, which represents imperative low-level logic that runs within the func. It can, for example, include loops and dictionary accesses. Finally, this low-level intermediate representation is compiled into bytecode, which represents the end game target of our compiler pipeline. At Lokad, we target the .NET bytecode, technically known as MSIL.
From a supply chain perspective, what is really interesting is that through this arguably complex compiler pipeline, we are reproducing the degree of integration found in Microsoft Excel. The language is integrated with the data layer and the UI/UX layer, allowing users to see and interact with the outputs of the program, just as they would with an Excel spreadsheet. However, unlike Excel, we delve into much more interesting territories for supply chain management by embracing relational concepts as first-class citizens, as well as mathematical optimization and machine learning.
Both mathematical optimization and machine learning in this pipeline go through the entire pipeline, instead of merely calling a library that sits somewhere. Having machine learning as a first-class citizen in the pipeline allows for more intelligible error messages, which makes a big difference in terms of productivity for supply chain experts.

As a final topic, compilers nowadays almost always target a virtual machine, but these virtual machines, in turn, are compiled towards another virtual machine. On the screen, the typical VM layers found in a server-based setup are very similar to what we have with an Envision script. I’ve just presented the compiler pipeline, but fundamentally, it would be pretty much the same stack if we were thinking about a Python script or an Excel spreadsheet operated from a server. When designing a compiler, you essentially choose the layer at which you are going to inject the code. The deeper the layer, the more technicalities you have to address. To choose the layer, there are a series of concerns that need to be addressed.
First, there is security. How do you protect your memory and what should or shouldn’t the program access? If you have a generic programming language, your options are limited. You might need to operate at the guest operating system level, although even that might not be very secure. There are ways to sandbox, but it’s very tricky, so you might even have to go lower than that.
Second, there is the concern of low-level features you’re interested in. For example, this could be important if you want to achieve a more performant execution, reducing the amount of computing resources needed to complete your program. You can decide to go sufficiently low so that you manage the memory and threads. However, with this power comes the responsibility of actually managing the memory and threads.
Third, there are convenience features like garbage collection, stack trace, debugger, and profiler. Typically, all the instrumentation around the compiler is more complex than the compiler itself. The amount of convenience features that you benefit from should not be underestimated.
Fourth, there are resource allocation concerns. If you’re operating with an Excel spreadsheet on your desktop, Excel can consume all the computing resources in your workstation. However, with Envision or SQL, you have multiple users to serve, and you have to decide how to allocate resources. Furthermore, with Envision, it’s not just multiple users, but multiple companies to serve, as Lokad is multi-tenant. This makes sense in supply chain because the need for computational resources is very intermittent for most supply chains.
Typically, you only need a very intense burst of compute for something like half an hour or maybe one hour, and then nothing for the next 23 hours. Then, rinse and repeat on a daily basis. If you were to allocate hardware computing resources to one company, those resources would remain unused 90% of the time or even more. So, you want to be able to spread the workload across many machines and over many companies, potentially companies that operate over various time zones.
Lastly, there’s the concern of the ecosystem. The idea is that when you decide on a specific layer and a specific VM to target for your compiler, it will be fairly convenient to integrate and interface your compiler with whatever is also targeting the exact same virtual machines. This brings up the question of the ecosystem: what can you find at the same level as what you target, in order not to reinvent the wheel for every single tidbit involved in your whole stack? This is the last and important concern.

In conclusion, congratulations to the happy few who made it this far in this series of supply chain lectures. This is probably one of the most technical lectures so far. Compilers are an arguably very technical piece; however, the reality of modern supply chains is that everything gets mediated through a programming language. There is no such thing anymore as a raw, directly observable supply chain. The only way to observe a supply chain is through the mediation of electronic records produced by all the pieces of enterprise software constituting the applicative landscape. Thus, a programming language is needed, and by default, this programming language happens to be Excel.
However, if we want to do better than Excel, we need to think hard about what “better” even means from a supply chain perspective and what it means in terms of programming languages. If a company doesn’t have the right strategy or culture, no technology will save it. However, if the strategy and culture are sound, then tooling really matters. Tooling, including programming languages, will define your capacity to execute, the productivity you can expect from your supply chain experts, and the performance you will get out of your supply chain when turning macro strategy into the thousands of mundane daily decisions your supply chain needs to make. Being able to assess the adequacy of the tools, including programming languages you intend to use to address supply chain challenges, is of primary importance. If you’re not able to assess, then it’s just complete cargo cult.

The next lecture will be about software engineering. Today, we discussed the tooling; however, next time, we will discuss the people who use the tools and what sort of teamwork is required to do the job well. The lecture will happen on the same day of the week, Wednesday, at 3 p.m., Paris time.
Now, I will have a look at the questions.
Question: When selecting software for supply chains, how can enterprises that are not tech-savvy evaluate if the compiler and programming are appropriate for their needs?
Well, I’m pretty sure that a typical company that operates a typical supply chain does not have the qualifications to engineer a vehicle, yet they manage to purchase trucks that are adequate for their supply chain and transportation requirements. It’s not because you’re not an expert and not able to rebuild and re-engineer a truck that you can’t have a very solid opinion on whether it’s a good truck for your transportation needs. So, I’m not saying that companies that are not tech-savvy should make some incredible leap forward and suddenly become experts in the design of compilers. However, I believe that in just an hour and a half, we covered quite a lot of ground. With 10 more hours of a more detailed and slower-paced introduction, you would learn everything you’d ever need to know in terms of language design for supply chain purposes.
There is a difference between being an expert and being so incredibly ignorant that people can sell you a scooter pretending it’s a truck. If we were to translate this sort of ignorance that I observed in terms of enterprise software design to the automotive industry, people would claim that a scooter is a semi and vice versa, and get away with it.
This series of lectures is about auxiliary sciences, so there is no intent for people who want to be supply chain practitioners to become experts in these domains. Nevertheless, by having some entry-level knowledge, you can go very far in assessing. Most of the time, you only need to have just enough knowledge to ask tough questions. If the vendor gives you a nonsensical answer, it doesn’t look good. If you don’t even know which technical questions to ask, you can be fooled.
My suggestion is that you don’t need to become incredibly tech-savvy; you just need to be savvy enough to be an entry-level amateur who can poke holes and assess whether the whole thing falls apart or if there’s actual substance behind it. The same is true for mathematical optimization, machine learning, CPUs, and so on. The idea is to know enough to differentiate between something fraudulent and something legitimate.
Question: Did you directly address the issue with existing programming languages not designed for supply chain?
This is a very good question. Engineering a brand new programming language may seem completely nuts. Why not just go for something already well-established, like Python, and bring in the small modifications we need? It would have been an option. The problem is that the main issue is not really what we need to add to those languages but what we need to remove.
My main concern with Python is not that it doesn’t have a probabilistic algebra or that it doesn’t have a relational algebra built-in. My number one criticism is that it is a fully capable, generic programming language, and thus it exposes the person who is going to write code to all sorts of concepts, like object-oriented programming for Python, that are completely inconsequential as far as supply chain is concerned. The problem was not so much to take a language and add something, but to take a language and try to remove tons of things. However, the problem is that as soon as you remove stuff from an existing programming language, you break everything.
For example, the first release of Python was in 1990, so it is a 30-year-old programming language. The amount of code in a popular stack like Python is absolutely gigantic, and for good reason. I’m not criticizing it; it is a very solid stack, but it is also an enormous one. So in the end, we assessed various options: take a programming language, subtract tons of things until we are satisfied with what we have, or consider that all those programming languages have tons of legacy of their own.
We assessed how much effort it was to create a brand new language, and in the end, it was very much in favor of creating a new language. Engineering a new programming language is a super-established field, so although it may sound incredible, it is not. There are hundreds of books that give you recipes, and it is now even accessible to computer science students. There are even professors in computer science departments that give an assignment to their students in one semester to create a compiler for a new programming language.
In the end, we decided that supply chains were massive enough to warrant a dedicated effort. Yes, you can always recycle stuff that was not designed for supply chains, but supply chains are a worldwide, massive industry and set of problems. So we thought, considering the scale we’re looking at, it makes sense to do the right thing and create something directly for supply chain as opposed to accidental recycling.
Question: For supply chain optimization, Envision is appropriate as it comprises SQL, Python, etc. However, for WMS, ERP, where process flow is key rather than mathematical optimization, how can you evaluate its compiler and programming language?
That is a very good question. I have been personally toying with the idea that there are actors in this industry who have actually engineered programming languages of their own, just for the benefits of implementing something completely transactional in nature, workflow-oriented. Supply chain, the way I see it, is essentially about predictive optimization. However, Mr. Nannani is completely correct; what about all the management part, like ERP, WMS, etc.?
It turns out that there are many companies in this field who have crafted their own programming language. I mentioned SAP, which has ABAP, designed just for that. Unfortunately, ABAP didn’t age very well, in my opinion. There are plenty of things in ABAP that don’t really make sense in the 21st century. You can really see that this thing was designed in ‘83, and it shows. For example, in Microsoft Dynamics, the ERP has a programming language of its own. Dynamics AX has its own programming language, and there are many ERP projects that, to a large extent, bring their own programming language. So, it does exist.
Now, are those languages really the pinnacle of what we can do in terms of modern, state-of-the-art programming languages in 2021? I don’t think so, and that’s also the problem that I was saying: enterprise software vendors keep reinventing programming languages, but usually, they do a very poor job at that. It’s just haphazard engineering design. They don’t even take the time to read the many books that are available on the market, and then there are poor engineers that are stuck with a hot pile of mess.
Back to your question, I’ve been toying with the idea of Lokad venturing into this area and creating a language that was designed not for optimization but for supporting the workflow. However, at this point, the growth of Lokad is so much that we can’t fork off and deal with the workflows. I am absolutely certain that this is spot on, and there will be new actors that will emerge and do a very good job for the management part of the problem. Lokad is only tackling the optimization part of supply chains; there is also the management part.
Question: Python is currently seen as a standard programming language. Are there any ongoing evolutions in the market?
That is a very good question. You see, when people tell me “the standards,” I’ve been around long enough to see standards come and go. I’m not very old, but when I was in high school, the standard was C++. In the ’90s, C++ was the standard. Why would you do it any other way? Then came Java, around the year 2000, and the combination of Java and XML was the standard.
People even said that universities at the time had turned into “Java schools.” That was literally the term of the day around the year 2000; people were saying, “This is not a computer science university anymore; this is just a Java school.” A few years down the road, when I founded Lokad, the programming language for anything relevant to statistics was still R. Python was still very marginal, and R was absolutely dominating the field in terms of statistical analysis.
As we progress in terms of programming languages, C++ faded away. Microsoft introduced C# in 2002 and the .NET platform, which cannibalized a significant part of the C++ ecosystem. A big part of the C++ developers worldwide were at Microsoft, a very massive company. The point that I’m getting at is that there has been a complete ongoing evolution, and every single year, people look at this as if there was a standard, but this standard changes all the time.
JavaScript had been around for 20 years, but it was nothing significant. Then, a book published around 2009 or 2012 called “JavaScript: The Good Parts” revealed that JavaScript was not completely insane. You could use JavaScript for a real project without losing your sanity; you just had to stick with the good parts. Suddenly, JavaScript was all the rage, and people started using it server-side with a system called Node.js.
Python only rose to prominence a few years back, after the Python community underwent a grueling upgrade from version 2.7 to version 3.x. At the end of this upgrade, interest in Python was renewed. However, there are many dangers that loom ahead for Python. It’s not a very good language by the standards of the 21st century. It’s a 30-year-old language, and it shows its age. If you want something better in every dimension except maturity, you could look at Julia. Julia is superior in almost every way to Python for data science, except for maturity, where Julia is still years behind.
There are tons of ongoing evolutions, and it’s easy to mistake the state of the industry for something that is a standard that is supposed to last. For example, in the Apple ecosystem, there was Objective-C, and then Apple decided to produce Swift as a replacement, which is now replacing Objective-C. The programming language landscape is still very much evolving, and although it takes time, if we look at the ecosystem ten years ahead, there will likely be a significant amount of evolution. Python may not emerge as the dominant programming language, as there are many rival options that bring better answers.
Question: Food companies and e-commerce startups often think they can win the battle with data science teams and general-purpose languages. What would be your top selling point to make them refine this approach and make them realize they need something more problem-specific?
As I said, this is the problem with the Dunning-Kruger effect. You give a software engineer a mixed-integer linear programming system to do integer programming, and a week afterward, this person will think they have suddenly become an expert in discrete optimization. So, how do I win the battle? Truth to be told, usually, we don’t win them. What I do is describe the way the catastrophes will unfold.
It’s straightforward when you go with generic blocks of technology to create fantastic prototypes. These prototypes work brilliantly due to the Star Wars delusion – you have just your piece of technology in isolation. As these companies start trying to bring those things to production, they will struggle, most of the time due to very mundane problems. They will face ongoing integration issues, not like Google or Microsoft or Amazon, who can afford to have a thousand engineers to deal with all the plumbing.
TensorFlow, for example, is challenging to integrate. Google has the 1000 engineers it takes to glue TensorFlow into all their data pipelines and applications for their purposes. But the question is, can startups or e-commerce companies afford to have that many people take care of all the plumbing? Usually, the answer is no. People imagine by just picking these tools, they will be able to cherry-pick things and put them together, and magically it works. But it doesn’t. It requires a massive amount of engineering.
By the way, some enterprise software vendors are suffering from the exact same problem. They have way too many components in their solution, and that explains why deploying a solution, with no customization whatsoever, already takes months because there are so many shaky parts in the system that are only loosely integrated. It becomes very difficult.
I guess this was the last question. See you next time.


