00:28 Introduction
00:43 Robert A. Heinlein
03:03 The story so far
06:52 A selection of paradigms
08:20 Static Analysis
18:26 Array programming
28:08 Hardware miscibility
35:38 Probabilistic programming
40:53 Differentiable programming
55:12 Versioning code+data
01:00:01 Secure programming
01:05:37 In conclusion, tooling matters in Supply Chain too
01:06:40 Upcoming lecture and audience questions
Description
While mainstream supply chain theory struggles to prevail in companies at large, one tool; namely Microsoft Excel, has enjoyed considerable operational success. Re-implementing the numerical recipes of the mainstream supply chain theory via spreadsheets is trivial, yet, this is not what happened in practice despite awareness of the theory. We demonstrate that spreadsheets won by adopting programming paradigms that proved superior to deliver supply chain results.
Full transcript

Hi everyone, welcome to this series of supply chain lectures. I am Joannes Vermorel, and today I will be presenting my fourth lecture: Programming Paradigms for Supply Chain.

So when I am asked, “Mr. Vermorel, what do you think are the areas of most interest to you in terms of supply chain knowledge?” one of my top answers is usually programming paradigms. And then, not too frequently, but frequently enough, the reaction of the person I’m talking to is, “Programming paradigms, Mr. Vermorel? What the hell are you even talking about? How is it even remotely relevant to the task at hand?” And those sort of reactions, obviously, they are not so frequent, but when they happen, they invariably remind me of this completely incredible quote by Robert A. Heinlein, who is considered as the dean of science fiction writers.
Heinlein has a fantastic quote about the competent man, which highlights the importance of competency in various fields, especially in supply chain where we have wicked problems on our hands. These problems are almost as challenging as life itself, and I believe that it’s really worth your time to explore the idea of programming paradigms, as it could bring a lot of value to your supply chain.
So far, in the first lecture, we have seen that supply chain problems are wicked. Anyone who talks of optimal solutions is missing the point; there is nothing even remotely close to optimality. In the second lecture, I outlined the Quantitative Supply Chain, a vision with five key requirements for greatness in supply chain management. These requirements are not sufficient on their own, but they cannot be bypassed if you want to achieve greatness.
In the third lecture, I discussed software product delivery in the context of supply chain optimization. I defended the proposition that supply chain optimization requires a software product to be addressed properly in a capitalistic fashion, but you cannot find such a product on the shelf. There is too much diversity, and the challenges faced are way beyond the technologies that we have at present time. So, it’s going to be, by necessity, something completely bespoke. Thus, if it is a software product that is going to be bespoke for the company or the supply chain of interest, there is a question of what are the proper tools to actually deliver this product. That brings me to the topic of today: the proper tool starts with the right programming paradigms, because we are going to have to program this product one way or another.

So far, we require programmatic capabilities to deal with the optimization side of the problem, not to be confused with the management side. What we have seen, which was the topic of my previous lecture, is that Microsoft Excel has been the winner so far. From very small companies to very large companies, it’s ubiquitous, it’s used everywhere. Even in companies that have invested millions of dollars in super-smart systems, Excel still rules, and why? Because it has the right programming properties. It’s very expressive, agile, accessible, and maintainable. However, Excel is not the end game. I firmly believe that we can do so much more, but we need to have the right tools, mindset, insights, and programming paradigms.

Programming paradigms might feel overly obscure to the audience, but it’s actually a field of study that has been intensively studied for the last five decades. There has been an immense amount of work done in this field of study. It’s not widely known to a wider audience, but there are entire libraries filled with high-quality work that has been done by many people. So today, I am going to introduce a series of seven paradigms that Lokad has adopted. We did not invent any of these ideas; we took them from people who invented them before us. All these paradigms have been implemented in Lokad’s software product, and after nearly a decade of running Lokad in production, leveraging these paradigms, I believe they have been absolutely critical to our operational success so far.

Let’s proceed through this list with static analysis. The problem here is complexity. How do you deal with complexity in supply chain? You are going to face enterprise systems that have hundreds of tables, each with dozens of fields. If you’re considering a problem as simple as inventory replenishment in a warehouse, you have so many things to take into account. You can have MOQs, price breaks, forecasts of demand, forecasts of lead times, and all kinds of returns. You can have shelf space limitations, reception capacity limits, and expiration dates that make some of your batches obsolete. So, you end up with tons of things to consider. In supply chain, the idea of “move fast and break things” is just not the right mindset. If you inadvertently order one million dollars’ worth of merchandise that you don’t need at all, this is a very costly mistake. You can’t have a piece of software driving your supply chain, making routine decisions, and when there is a bug, it costs millions. We need to have something with a very high degree of correctness by design. We do not want to discover the bugs in production. This is very different from your average software where a crash is no big deal.
When it comes to supply chain optimization, this is not your usual problem. If you just passed a massive, incorrect order to a supplier, you can’t just phone them a week later to say, “Oh, my mistake, no, forget about that, we never ordered that.” Those mistakes are going to cost a lot of money. Static analysis is called this because it’s about analyzing a program without running it. The idea is that you have a program written with statements, keywords, and everything, and without even executing this program, can you already tell if the program exhibits problems that would almost certainly negatively impact your production, especially your supply chain production? The answer is yes. These techniques do exist, and they are implemented and exceedingly valuable.
Just to give an example, you can see an Envision screenshot on the screen. Envision is a domain-specific programming language that has been engineered for almost a decade by Lokad and is dedicated to the predictive optimization of supply chain. What you are seeing is a screenshot of the code editor of Envision, a web app that you can use online to edit code. The syntax is heavily influenced by Python. In this tiny screenshot, with just four lines, I’m illustrating the idea that if you’re writing a large piece of logic for inventory replenishment in a warehouse, and you introduce some economic variables, like price breaks, through a logical analysis of the program, you can see that those price breaks have no relationship whatsoever with the end results that are returned by the program, which are the quantities to be replenished. Here, you have an obvious problem. You have introduced an important variable, price breaks, and those price breaks logically have no influence on the end results. So here, we have a problem that can be detected through static analysis. It’s an obvious problem because if we introduce variables in the code that don’t have any impact on the output of the program, then they serve no purpose at all. In this case, we are faced with two options: either those variables are actually dead code, and the program should not compile (you should just get rid of this dead code to reduce complexity and not pile up accidental complexity), or it was a genuine mistake and there is an important economic variable that should have been plugged into your calculation, but you dropped the ball due to distraction or some other reason.
Static analysis is absolutely fundamental to achieve any degree of correctness by design. It’s about fixing things at compile time when you write the code, even before you touch the data. If problems emerge when you run them, chances are that your problems will only happen during the night when you have the nightly batch driving the warehouse replenishment. The program is likely to run at odd hours when nobody is attending it, so you don’t want something to crash while there is nobody in front of the program. It should crash at the time when people are actually writing the code.
Static analysis has many purposes. For example, at Lokad, we use static analysis for the WYSIWYG edition of dashboards. WYSIWYG stands for “what you see is what you get.” Imagine you’re building a dashboard for reporting, with line charts, bar charts, tables, colors, and various styling effects. You want to be able to do that visually, not tweak the style of your dashboard through the code, as it’s very cumbersome. All the settings you’ve implemented are going to be re-injected into the code itself, and that is done through static analysis.
Another aspect at Lokad, which may not be of such importance for supply chain overall but certainly critical for undertaking the project, was dealing with a programming language called Envision that we are engineering. We knew from day one, almost a decade ago, that mistakes were going to be made. We didn’t have a crystal ball to just have the perfect vision from day one. The question was, how can we make sure that we can fix those design mistakes in the programming language itself as conveniently as possible? Here, Python was a warning tale for me.
Python, which is not a new language, was first released in 1991, almost 30 years ago. The migration from Python 2 to Python 3 took the entire community almost a decade, and it was a nightmarish process, very painful for the companies involved in this migration. My perception was that the language itself did not have enough constructs. It was not designed in a way that you could migrate programs from one version of the programming language to another version. It was actually exceedingly difficult to do so in a completely automated manner, and that’s because Python has not been engineered with static analysis in mind. When you have a programming language for supply chain, you really want one that has excellent quality in terms of static analysis because your programs will be long-lived. Supply chains don’t have the luxury to say, “Hold on for three months; we are just rewriting the code. Wait for us; the cavalry is coming. It’s just not going to be working for a couple of months.” It’s literally akin to fixing a train while the train is running on the tracks at full speed, and you want to fix the engine while the train is working. That’s what it looks like fixing supply chain stuff that is actually in production. You don’t have the luxury to just pause the system; it never pauses.

The second paradigm is array programming. We want to have complexity under control, as that’s a big recurring theme in supply chains. We want to have logic where we don’t have certain classes of programming errors. For example, whenever you have loops or branches that are written explicitly by programmers, you expose yourself to entire classes of very difficult problems. It becomes exceedingly hard when people can just write arbitrary loops to have guarantees on the duration of the calculation. While it might seem like a niche problem, it’s not quite the case in supply chain optimization.
In practice, let’s say you have a retail chain. At midnight, they will have completely consolidated all the sales from the entire network, and the data will be consolidated and passed to some kind of system for optimization. This system will have exactly a 60-minute window to do the forecasting, inventory optimization, and reallocation decisions for every single store of the network. Once it’s done, the results will be passed to the warehouse management system so that they can start preparing all the shipments. The trucks are going to be loaded, maybe at 5:00 AM, and by 9:00 AM, the stores are opening with the merchandise already received and put on the shelves.
However, you have a very strict timing, and if your calculation goes outside of this 60-minute window, you’re putting the entire supply chain execution at risk. You don’t want something where you’re just going to discover in production how much time things take. If you have loops where people can decide how many iterations they are going to have, it’s very difficult to have any proof of the duration of your calculation. Bear in mind that this is supply chain optimization we are talking about. You don’t have the luxury to do peer review and double-check everything. Sometimes, due to the pandemic, some countries are shutting down while others are reopening quite erratically, usually with a 24-hour notice. You need to react swiftly.
So, array programming is the idea that you can operate directly on arrays. If we look at the snippet of code that we have here, this is Envision code, the DSL of Lokad. To understand what’s going on, you have to understand that when I write “orders.amounts”, what comes is a variable and the “orders” is actually a table in the sense of a relational table, as in a table in your database. For example, here in the first line, “amounts” would be a column in the table. On line one, what I’m doing is that I’m literally saying for every single line of the orders table, I am just going to take the “quantity”, which is a column, and multiply it by “price”, and then I get a third column that is dynamically generated, which is “amount”.
By the way, the modern term for array programming nowadays is also known as data frame programming. The field of study is quite ancient; it goes back three or four decades, maybe even four or five. It has been known as array programming even if nowadays people are usually more familiar with the idea of data frames. On line two, what we are doing is that we are doing a filter, just like SQL. We are filtering the dates, and it just so happens that the orders table has a date. It’s going to be filtered, and I say “date that is greater than today minus 365”, so it’s days. We keep the data from last year, and then we are writing “products.soldLastYear = SUM(orders.amount)”.
Now, the interesting thing is that we have what we call a natural join between products and orders. Why? Because every order line is associated with one product and one product only, and one product is associated with zero or more order lines. In this configuration, you can directly say, “I want to compute something at the product level that is just a sum of whatever is happening at the orders level,” and that’s exactly what is being done at line nine. You might notice the syntax is very bare; you don’t have many accidentals or technicalities. I would contend that this code is almost entirely devoid of any accidentals when it comes to data frame programming. Then, on lines 10, 11, and 12, we are just putting a table on display on our dashboard, which can be done very conveniently: “LIST(PRODUCTS)”, and then “TO(products)”.
There are many upsides of array programming for supply chains. First, it eliminates entire classes of problems. You’re not going to have off-by-one bugs in your arrays. It’s going to be way easier to parallelize and even distribute the computation. That’s very interesting because it means that you can write a program and have the program executed not on one local machine but directly on a fleet of machines that live in the cloud, and by the way, this is exactly what is being done at Lokad. This automatic parallelization is of super high interest.
You see, the way it works is that when you do supply chain optimization, your typical consumption patterns in terms of computing hardware are super intermittent. If I go back to the example I was giving about the 60-minute window for the retail networks during store replenishment, it means that there is one hour per day where you need compute power to do all of your calculations, but the rest of the time, the other 23 hours, you don’t need that. So what you want is a program that, when you’re about to run it, is going to spread on many machines and then, once it’s done, it’s just going to release all those machines so that other calculations can take place. The alternative would be having many machines that you’re renting and paying for all day long but only using them 5% of the time, which is very inefficient.
This idea that you can distribute over many machines rapidly and predictably, and then surrender the processing power, needs the cloud in a multi-tenant setup and a series of other things on top that Lokad is doing. But first and foremost, it needs cooperation from the programming language itself. It’s something that is just not feasible with a generic programming language like Python, because the language itself does not lend itself to this sort of very smart and relevant approach. This is more than just tricks; it’s literally about dividing your IT hardware costs by 20, massively accelerating the execution, and eliminating entire classes of potential bugs in your supply chain. This is game-changing.
Array programming already exists in many aspects, such as in NumPy and pandas in Python, which are so popular for the data scientist segment of the audience. But the question that I have for you is, if it’s so important and useful, why aren’t these things first-class citizens of the language itself? If all you do is channel through NumPy, then NumPy should be a first-class citizen. I would say you can go even better than NumPy. NumPy is just about array programming on one machine, but why not do array programming on a fleet of machines? It’s much more powerful and much more adequate when you have a cloud with accessible hardware capability.
So, what is going to be the bottleneck in supply chain optimization? There is this saying by Goldratt that states, “Any improvement brought beside the bottleneck in a supply chain is an illusion,” and I very much agree with this statement. Realistically, when we want to do supply chain optimization, the bottleneck will be people, and more specifically, the supply chain scientists who, unfortunately for Lokad and my clients, don’t grow on trees.
The bottleneck is the supply chain scientists, the people who can craft the numeric recipes that factor in all the strategies of the company, the adversary behaviors of competitors, and that turn all this intelligence into something mechanical that can be executed at scale. The tragedy of the naive way of doing data science, when I started my PhD, which I never completed by the way, was that I could see everyone in the lab was literally doing data science. Most people were writing code for some kind of advanced machine learning model, they would press enter and then start waiting. If you have a large dataset, say 5-10 gigabytes, it’s not going to be real-time. So, the entire lab was filled with people who would write a few lines, press enter, and then go and grab a cup of coffee or read something online. Thus, productivity was exceedingly low.
When I went on to create my own company, I had it in my mind that I didn’t want to end up paying an army of super smart people who spend most of their day sipping coffee, waiting for their programs to complete so they can have results and move on. In theory, they could parallelize many things at once and run experiments, but in practice, I’ve never really seen that. Intellectually, when you’re engaged in finding a solution for a problem, you want to test your hypothesis, and you need the result to move on. It’s very hard to multitask on highly technical stuff and chase multiple intellectual tracks at the same time.
However, there was a silver lining. Data scientists, and now supply chain scientists at Lokad, don’t end up writing a thousand lines of code and then saying “please run.” They usually add two lines to a script that is a thousand lines long, and then they ask for the script to be run. This script is running against the exact same data they have just executed a few minutes before. It’s almost exactly the same logic, except for those two lines. So, how can you process terabytes of data in seconds instead of several minutes? The answer is, if for the former execution of the script, you’ve recorded all the intermediate steps of the calculation and put them on storage (typically solid-state drives or SSDs), which are very cheap, fast, and convenient.
The next time you run your program, the system will notice that it’s almost the same script. It’s going to do a diff, and see that in terms of the compute graph, it’s almost identical, except for a few bits. In terms of data, it’s usually 100% identical. Sometimes there are a few changes, but almost nothing. The system will auto-diagnose that you have only a few things that you need to compute, so you can have the results in seconds. This can dramatically boost the productivity of your supply chain scientist. You can go from people who press enter and wait for 20 minutes for the result to something where they press enter and 5 or 10 seconds later, they have the result and can move on.
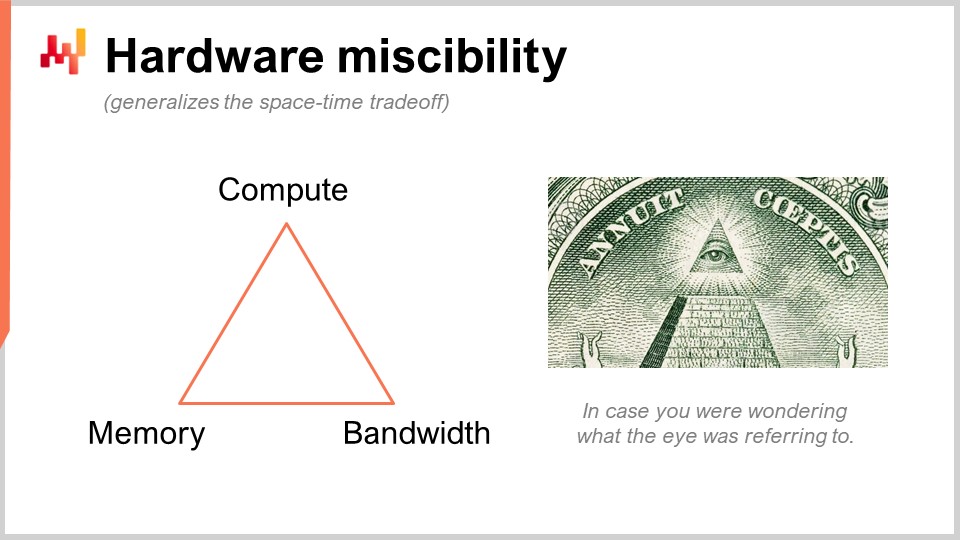
I’m talking about something that may seem super obscure, but in practice, we are talking about something that has a 10x impact on productivity. This is massive. So what we are doing here is using a clever trick that Lokad did not invent. We are substituting one raw computing resource, which is compute, for another, which is memory and storage. We have the fundamental computing resources: compute, memory (either volatile or persistent), and bandwidth. These are the fundamental resources that you pay for when you buy resources on a cloud computing platform. You can actually substitute one resource for another, and the goal is to get the biggest bang for your buck.
When people say you should be using in-memory computing, I would say that’s nonsense. If you say in-memory computing, it means that you’re putting a design emphasis on one resource versus all the others. But no, there are trade-offs, and the interesting thing is that you can have a programming language and environment that makes these trade-offs and perspectives easier to implement. In a regular general purpose programming language, it is possible to do that, but you have to do it manually. This means that the person doing it has to be a professional software engineer. A supply chain scientist is not going to perform these low-level operations with the fundamental computing resources of your platform. This has to be engineered at the level of the programming language itself.
Now, let’s talk about probabilistic programming. In the second lecture where I introduced the vision for the quantitative supply chain, my first requirement was that we need to look at all the possible futures. The technical answer to this requirement is probabilistic forecasting. You want to deal with futures where you have probabilities. All futures are possible, but they are not all equally probable. You need to have an algebra where you can do calculations with uncertainty. One of my big criticisms of Excel is that it’s exceedingly difficult to represent uncertainty in a spreadsheet, regardless of whether it’s Excel or any more modern cloud-based flavor. In a spreadsheet, it’s very difficult to represent uncertainty because you need something better than numbers.
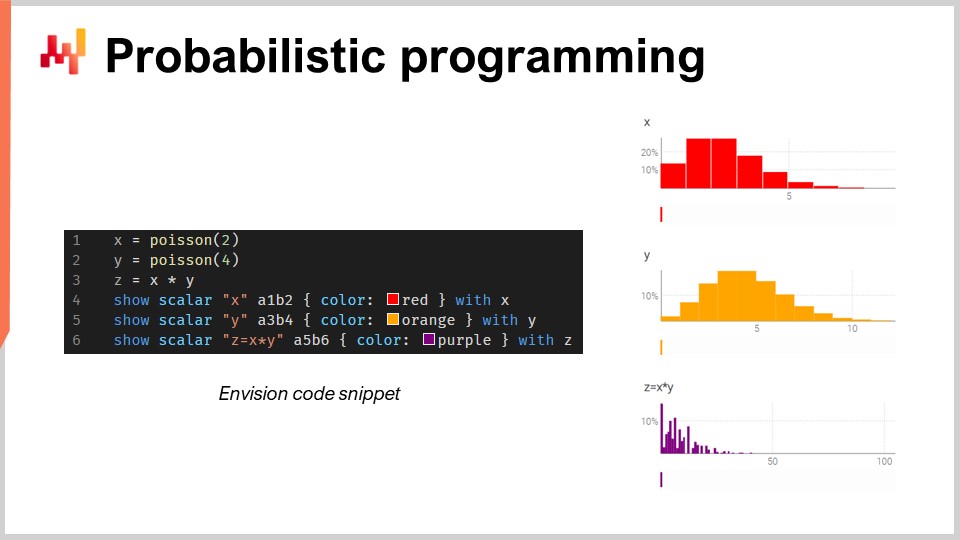
In this small snippet, I’m illustrating the algebra of random variables, which is a native feature of Envision. In line one, I’m generating a Poisson distribution that is discrete, with a mean of 2, and I put that in the variable X. Then, I’m doing the same for another Poisson distribution, Y. Then, I am calculating Z as the multiplication of X times Y. This operation, the multiplication of random variables, may seem very bizarre. Why do you even need this sort of thing from a supply chain perspective? Let me give you an example.
Let’s say you’re in the automotive aftermarket and you’re selling brake pads. People don’t buy brake pads by the unit; they either buy two or four. So the question is, if you want to do a forecast, you may want to forecast the probabilities that clients are going to show up to actually buy a certain type of brake pads. That’s going to be your first random variable that gives you the probability of observing zero units of demand, one unit of demand, two, three, four, etc. for the brake pads. Then you will have another probability distribution that represents whether people are going to buy two or four brake pads. Maybe it’s going to be 50-50, or maybe it’s going to be 10 percent buying two and 90 percent buying four. The thing is that you have these two angles, and if you want to know the actual total consumption of brake pads, you want to multiply the probability of having a client showing up for this brake pad and then the probability distribution of buying either two or four. Thus, you need to have this multiplication of these two uncertain quantities.
Here, I’m assuming that the two random variables are independent. By the way, this multiplication of random variables is known in mathematics as a discrete convolution. You can see on the screenshot the dashboard generated by Envision. In the first three lines, I’m doing this random algebra calculation, and then in lines four, five, and six, I’m putting those things on display in the webpage, in the dashboard generated by the script. I’m plotting A1, B2, for example, just like in an Excel grid. The Lokad dashboards are organized similarly to Excel grids, with positions having columns B, C, etc., and rows 1, 2, 3, 4, 5.
You can see that the discrete convolution, Z, has this very bizarre, super spiky pattern that is actually very commonly found in supply chains when people can buy packs, lots, or multiples. In this sort of situation, it’s usually better to decompose the sources of the multiplicative events associated with the lot or the pack. You need to have a programming language that has these capabilities available at your fingertips, as first-class citizens. That’s exactly what probabilistic programming is about, and that’s how we implemented it in Envision.

Now, let’s discuss differentiable programming. I must put a caveat here: I don’t expect the audience to really understand what is going on, and I apologize for that. It’s not that your intelligence is lacking; it’s just that this topic deserves a whole series of lectures. In fact, if you look at the plan for the upcoming lectures, there is a whole series dedicated to differentiable programming. I’m going to go super fast, and it’s going to be fairly cryptic, so I apologize in advance.
Let’s proceed with the supply chain problem of interest here, which is cannibalization and substitution. These problems are very interesting, and they are probably where time series forecasting, which is ubiquitous, fails in the most brutal way. Why? Because frequently, we have clients or prospects that come to me and ask if we can do, for example, 13-week ahead forecasts for certain items like backpacks. I would say yes, we can, but obviously, if we take one backpack and we want to forecast the demand for this product, it massively depends on what you’re doing with your other backpacks. If you have just one backpack, then maybe you’re going to concentrate all the demand for backpacks on this one product. If you introduce 10 different variants, obviously there will be tons of cannibalization. You’re not going to multiply the total amount of sales by a factor of 10 just because you’ve multiplied the number of references by 10. So obviously, you have cannibalization and substitution taking place. These phenomena are prevalent in supply chains.
How do you analyze cannibalization or substitution? The way we are doing it at Lokad, and I don’t pretend that it’s the only way, but it’s certainly a way that works, is typically by looking at the graph that connects clients and products. Why is that? Because cannibalization happens when products are in competition with themselves for the same clients. Cannibalization is literally the reflection that you have a client with a need, but they have preferences and are going to choose one product among the set of products that fit their affinity, and pick only one. That’s the essence of cannibalization.
If you want to analyze that, you need to analyze not the time series of the sales, because you don’t capture this information in the first place. You want to analyze the graph that connects the historical transactions between clients and products. It turns out that in most businesses, this data is readily available. For e-commerce, that’s a given. Every unit that you sell, you know the client. In B2B, it’s the same thing. Even in B2C in retail, most of the time, retail chains nowadays have loyalty programs where they know a double-digit percentage of the clients that show up with their cards, so you know who is buying what. Not for 100% of the traffic, but you don’t need that. If you have 10% and above of your historical transactions where you know the pair of clients and products, it’s good enough for this sort of analysis.
In this relatively small snippet, I’m going to detail an affinity analysis between clients and products. That’s literally the foundational step you need to take to do any kind of cannibalization analysis. Let’s have a look at what is happening in this code.
From lines one to five, this is very mundane; I’m just reading a flat file that contains a history of transactions. I’m just reading a CSV file that has four columns: date, product, client, and quantity. Something very basic. I’m not even using all those columns, but just to make the example a bit more concrete. In the transaction history, I assume that the clients are known for all those transactions. So, it’s very mundane; I’m just reading data from a table.
Then, in lines seven and eight, I’m merely creating the table for products and the table for clients. In a real production setup, I would typically not create those tables; I would read those tables from other flat files elsewhere. I wanted to keep the example super simple, so I am just extracting a product table from the products that I observed in the transaction history, and I do the same for clients. You see, it’s just a trick to keep it super simple.
Now, lines 10, 11, and 12 involve Latin spaces, and this is going to become a bit more obscure. First, on line 10, I am creating a table with 64 lines. The table doesn’t contain anything; it is only defined by the very fact that it has 64 lines, and that’s it. So this is like a placeholder, a trivial table with many lines and no columns. It’s not so useful just like that. Then, “P” is basically a Cartesian product, a mathematical operation with all the pairs. It’s a table where you have one line for every line in the products and every line in the table “L”. So, this table “P” has 64 more lines than the products table, and I’m doing the same thing for clients. I’m just inflating those tables through this extra dimension, which is this table “L”.
This will be my support for my Latin spaces, which is exactly what I’m going to learn. What I want to learn is, for every product, a Latin space which is going to be a vector of 64 values, and for every client, a Latin space of 64 values as well. If I want to know the affinity between a client and a product, I just want to be able to do the dot product between the two. The dot product is just the point-wise multiplication of all the terms of those two vectors, and then you do the sum. It may sound very technical, but it’s just point-wise multiplication plus sum – that’s the dot product.
These Latin spaces are just fancy jargon for creating a space with parameters that are a bit made up, where I just want to learn. All the differentiable programming magic happens in just five lines, from lines 14 to 18. I have one keyword, “autodiff”, and “transactions”, which says that this is a table of interest, a table of observations. I’m going to process this table line by line to do my learning process. In this block, I am declaring a set of parameters. The parameters are the things you want to learn, like numbers, but you just don’t know the values yet. Those things are just going to be initialized randomly, with random numbers.
I introduce “X”, “X*”, and “Y”. I’m not going to dive into what “X*” is doing exactly; maybe in the questions. I am returning an expression that is my loss function, and that’s the sum. The idea of collaborative filtering or matrix decomposition is just that you want to learn Latin spaces that fit all your edges in your bipartite graph. I know it’s a bit technical, but what we are doing is literally very simple, supply chain-wise. We are learning the affinity between products and clients.
I know that it seems probably super opaque, but stay with me, and there will be more lectures where I give you a more thoughtful introduction to that. The whole thing is done in five lines, and that’s completely remarkable. When I say five lines, I am not cheating by saying, “Look, it’s only five lines, but I am actually making a call to a third-party library of gigantic complexity where I’m burying all the intelligence.” No, no, no. Here, in this example, there is literally no machine learning magic besides the two keywords “autodiff” and “params”. “Autodiff” is used to define a block where differentiable programming will take place, and by the way, this is a block where I can program anything, so literally, I can inject our program. Then, I have “params” to declare my problems, and this is it. So, you see, there is no opaque magic going on; there is no one million line library in the background doing all the work for you. Everything you need to know is literally on this screen, and that’s the difference between a programming paradigm and a library. The programming paradigm gives you access to seemingly incredibly sophisticated capabilities, such as doing cannibalization analysis with just a few lines of code, without resorting to massive third-party libraries that wrap the complexity. It transcends the problem, making it way simpler, so you can have something that seems super complicated solved in just a few lines.
Now, a few words on how differentiable programming works. There are two insights. One is automatic differentiation. For those of you who have had the luxury of engineering training, you’ve seen two ways to compute derivatives. There is a symbolic derivative, for example, if you have x squared, you do the derivative by x, and it gives you 2x. That’s a symbolic derivative. Then you have the numerical derivative, so if you have a function f(x) that you want to differentiate, it’s going to be f’(x) ≈ (f(x + ε) - f(x))/ε. That’s the numeric derivation. Both are not suitable for what we are trying to do here. The symbolic derivation has problems of complexity, as your derivative might be a program that is much more complex than the original program. The numerical derivation is numerically unstable, so you will have plenty of problems with numerical stability.
Automatic differentiation is a fantastic idea dating from the 70s and rediscovered by the world at large in the last decade. It’s the idea that you can compute the derivative of an arbitrary computer program, which is mind-blowing. Even more mind-blowing, the program that is the derivative has the same computational complexity as the original program, which is stunning. Differentiable programming is just a combination of automatic differentiation and parameters that you want to learn.
So how do you learn? When you have the derivation, it means that you can bubble up gradients, and with stochastic gradient descent, you can make small adjustments to the values of the parameters. By tweaking those parameters, you will incrementally, through many iterations of stochastic gradient descent, converge to parameters that make sense and achieve what you want to learn or optimize.
Differentiable programming can be used for learning problems, like the one I’m illustrating, where I want to learn the affinity between my clients and my products. It can also be used for numerical optimization problems, such as optimizing things under constraints, and it’s very scalable as a paradigm. As you can see, this aspect has been made a first-class citizen in Envision. By the way, there are still a few things that are in progress in terms of Envision syntax, so don’t expect exactly those things yet; we are still refining a few aspects. But the essence is there. I’m not going to discuss the fine print of the few things that are still evolving.

Now let’s move to another problem relevant to the production readiness of your setup. Typically, in supply chain optimization, you face Heisenbugs. What is a Heisenbug? It’s a frustrating kind of bug where an optimization takes place and produces garbage results. For example, you had a batch calculation for inventory replenishment during the night, and in the morning, you discover that some of those results were nonsense, causing costly mistakes. You don’t want the problem to happen again, so you re-run your process. However, when you re-run the process, the problem is gone. You can’t reproduce the issue, and the Heisenbug does not manifest itself.
It may sound like a weird edge case, but in the first few years of Lokad, we faced these problems repeatedly. I’ve seen many supply chain initiatives, especially of the data science kind, fail due to unresolved Heisenbugs. They had bugs happening in production, tried to reproduce the issues locally but couldn’t, so the problems were never fixed. After a couple of months in panic mode, the entire project was usually quietly shut down, and people went back to using Excel spreadsheets.
If you want to achieve complete replicability of your logic, you need to version the code and the data. Most people in the audience who are software engineers or data scientists may be familiar with the idea of versioning the code. However, you also want to version all the data so that when your program executes, you know exactly which version of the code and data is being used. You may not be able to replicate the problem the next day because the data has changed due to new transactions or other factors, so the conditions triggering the bug in the first place are not present anymore.
You want to make sure that your programming environment can exactly replicate the logic and data as they were in production at a specific point in time. This requires complete versioning of everything. Again, the programming language and the programming stack have to cooperate to make this possible. It is achievable without the programming paradigm being a first-class citizen of your stack, but then the supply chain scientist must be exceedingly careful about all the things they do and the way they program. Otherwise, they won’t be able to replicate their results. This puts immense pressure on the shoulders of supply chain scientists, who are already under significant pressure from the supply chain itself. You don’t want these professionals to deal with accidental complexity, such as not being able to replicate their own results. At Lokad, we call this a “time machine” where you can replicate everything at any point in the past.
Beware, it’s not just about replicating what happened last night. Sometimes, you discover a mistake long after the fact. For example, if you place a purchase order with a supplier that has a three-month lead time, you may discover three months down the road that the order was nonsense. You need to go back three months in time to the point where you generated this bogus purchase order to figure out what the problem was. It’s not about versioning just the last few hours of work; it’s literally about having a complete history of the last year of execution.

Another concern is the rise of ransomware and cyberattacks on supply chains. These attacks are massively disruptive and can be very costly. When implementing software-driven solutions, you need to consider whether you’re making your company and supply chain more vulnerable to cyberattacks and risks. From this perspective, Excel and Python are not ideal. These components are programmable, which means they can carry numerous security vulnerabilities.
If you have a team of data scientists or supply chain scientists dealing with supply chain problems, they can’t afford the careful, iterative peer review process of code that is common in the software industry. If a tariff changes overnight or a warehouse gets flooded, you need a rapid response. You can’t spend weeks producing code specifications, reviews, and so on. The problem is that you’re giving programming capabilities to people who, by default, have the potential to bring harm to the company accidentally. It can be even worse if there’s an intentional rogue employee, but even putting that aside, you still have the problem of someone accidentally exposing an inner part of the IT systems. Remember, supply chain optimization systems, by definition, have access to a large amount of data across the entire company. This data is not just an asset but also a liability.
What you want is a programming paradigm that promotes secure programming. You want a programming language where there are entire classes of things you cannot do. For example, why should you have a programming language that can do system calls for supply chain optimization purposes? Python can do system calls, and so can Excel. But why would you want a programmable system with such capabilities in the first place? It’s like buying a gun to shoot yourself in the foot.
You want something where entire classes or features are absent because you don’t need them for supply chain optimization. If these features are present, they become a massive liability. If you introduce programmable capabilities without the tools that enforce secure programming by design, you increase the risk of cyberattacks and ransomware, making things worse.
Of course, it’s always possible to compensate by doubling the size of the cybersecurity team, but that’s very costly and not ideal when facing urgent supply chain situations. You need to act quickly and securely, without the time for the usual processes, reviews, and approvals. You also want secure programming that eliminates mundane problems like null reference exceptions, out-of-memory errors, off-by-one loops, and side effects.

In conclusion, tooling matters. There’s an adage: “Don’t bring a sword to a gunfight.” You need the proper tools and programming paradigms, not just the ones you learned at university. You need something professional and production-grade to meet your supply chain’s needs. While you might be able to achieve some results with subpar tools, it’s not going to be great. A fantastic musician can make music with just a spoon, but with a proper instrument, they can do so much better.

Now, let’s proceed with the questions. Please note that there is a delay of about 20 seconds, so there is some latency in the stream between the video you’re seeing and me reading your questions.
Question: What about dynamic programming in terms of operation research?
Dynamic programming, despite the name, is not a programming paradigm. It’s more an algorithmic technique. The idea is that if you want to perform an algorithmic task or solve a certain problem, you’ll repeat the same sub-operation very frequently. Dynamic programming is a specific case of the space-time trade-off I mentioned earlier, where you invest a little more in memory to save time on the compute side. It was one of the earliest algorithmic techniques, dating back to the 60s and 70s. It’s a good one, but the name is a bit unfortunate because there’s nothing really dynamic about it, and it’s not really about programming. It’s more about the conception of algorithms. So, to me, despite the name, it doesn’t qualify as a programming paradigm; it’s more of a specific algorithmic technique.
Question: Johannes, would you kindly provide some reference books that every good supply chain engineer should have? Unfortunately, I’m new to the field, and my current focus is data science and system engineering.
I have a very mixed opinion about the existing literature. In my first lecture, I presented two books that I believe to be the pinnacle of academic studies concerning supply chain. If you want to read two books, you can read those books. However, I have a constant problem with the books I’ve read so far. Basically, you have people who present collections of toy numerical recipes for idealized supply chains, and I believe that these books don’t approach the supply chain from the right angle, and they completely miss the point that it’s a wicked problem. There’s an extensive body of literature that is very technical, with equations, algorithms, theorems, and proofs, but I believe it misses the point entirely.
Then, you have another style of supply chain management books, which are more consultant-style. You can easily recognize these books because they use sports analogies every two pages. These books have all sorts of simplistic diagrams, like 2x2 variants of SWOT (Strengths, Weaknesses, Opportunities, Threats) diagrams, which I consider to be low-quality ways of reasoning. The problem with these books is that they tend to be better at understanding that supply chain is a wicked undertaking. They understand much better that it’s a game played by people, where all sorts of bizarre things can happen, and you can be smart in terms of ways. I give them credit for that. The problem with those books, typically written by consultants or professors of management schools, is that they are not very actionable. The message boils down to “be a better leader,” “be smarter,” “have more energy,” and for me, this is not actionable. It doesn’t give you elements that you can turn into something highly valuable, like software can.
So, I go back to the first lecture: read the two books if you want, but I’m not sure that it will be time well spent. It’s good to know what people have written. On the consultant side of the literature, my favorite is probably the work of Katana, which I didn’t list in the first lecture. Not everything is bad; some people have more talent, even if they are more consultant-ish. You can check the work of Katana; he has a book on dynamic supply chains. I will be listing the book in the references.
Question: How do you use parallelization when dealing with cannibalization or assortment decisions, where the problem is not easily parallelized?
Why is it not easily parallelized? Stochastic gradient descent is fairly trivial to parallelize. You have stochastic gradient steps that can be taken in random orders, and you can have multiple steps at the same time. So, I believe anything driven by stochastic gradient descent is fairly trivial to parallelize.
When dealing with cannibalization, what is more difficult is to deal with another sort of parallelization, which is what comes first. If I put this product first, then I make a forecast, but then I take another product, it modifies the landscape. The answer is you want to have a way to address the whole landscape frontally. You don’t say, “First, I introduce this product and do the forecast; I introduce another product and then redo the forecast, modifying the first one.” You just do it frontally, all those things at once, at the same time. You need more programming paradigms. The programming paradigms that I’ve introduced today can go a long way for that.
When it comes to assortment decisions, these sorts of problems don’t present any great difficulties for parallelization. The same thing applies if you have a worldwide retail network, and you want to optimize the assortment for all your stores. You can have computations that happen for all the stores in parallel. You don’t want to do it in sequence, where you optimize the assortment for one store and then move on to the next store. That’s the wrong way to do it, but you can optimize the network in parallel, propagate all the information, and then repeat. There are all sorts of techniques, and the tooling can greatly help you to do that in ways that are much easier.
Question: Are you using a graph database approach?
No, not in the technical, canonical sense. There are many graph databases on the market that are of great interest. What we are using internally at Lokad is a complete vertical integration through a unified, monolithic compiler stack to remove entirely all the traditional elements that you would find in a classical stack. This is how we achieve very good performance, in terms of compute performance, very close to the metal. Not because we are fantastically smart coders, but just because we have eliminated pretty much all the layers that traditionally exist. Lokad is using literally no database at all. We have a compiler that takes care of everything, down to the organization of the data structures for persistence. It’s a bit weird, but it’s much more efficient to do it that way, and this way, you play much more nicely with the fact that you compile a script toward a fleet of machines on the cloud. Your target platform, in terms of hardware, is not one machine; it’s a fleet of machines.
Question: What is your opinion on Power BI, which also runs Python codes and related algorithms like gradient descent, greedy, etc.?
The problem I have with anything related to business intelligence, Power BI being one of them, is that it has a paradigm that I think is inadequate for supply chain. You see all problems as a hypercube, where you have dimensions that you only slice and dice. At the core, you have a problem of expressivity, which is very limiting. When you end up using Power BI with Python in the middle, you need Python because the expressiveness related to the hypercube is very poor. To regain expressiveness, you add Python in the middle. However, remember what I said in the previous question about those layers: the curse of modern enterprise software is that you have too many layers. Every single layer that you add is going to introduce inefficiencies and bugs. If you use Power BI plus Python, you’re going to have way too many layers. So, you have Power BI that sits on top of other systems, meaning you already have multiple systems before Power BI. Then you have Power BI on top, and on top of Power BI, you have Python. But is Python acting on its own? No, chances are that you’re going to use Python libraries, like Pandas or NumPy. So, you have layers in Python that are going to pile up, and you end up with dozens of layers. You can have bugs in any of those layers, so the situation is going to be quite nightmarish.
I’m not a believer in those solutions where you just end up having a massive number of stacks. There’s this joke that in C++, you can always solve any problem by adding one more layer of indirection, including the problem of having too many layers of indirection. Obviously, this is a bit nonsensical as a statement, but I profoundly disagree with the approach where people have a product with an inadequate core design, and instead of tackling the problem frontally, they end up putting stuff on top while the foundations are shaky. This is not the way to do it, and you’re going to have poor productivity, ongoing battles with bugs that you’re never going to solve, and then, in terms of maintainability, it’s just a recipe for a nightmare.
Question: How can the results of a collaborative filtering analysis be plugged into the demand prediction algorithm for each product, like backpacks, for example?
I’m sorry, but I will address this topic in the next lecture. The short answer is that you don’t want to plug that into an existing prediction algorithm. You want to have something that is much more natively integrated. You don’t do that and then go back to your old ways of doing forecasting; instead, you just discard the old way of doing the forecast and do something radically different that leverages that. But I will discuss this in a later lecture. It would be too much for today.
I guess this is it for this lecture. Thank you very much, everyone, for attending. The next lecture will be on Wednesday, January 6th, same time, same day of the week. I will be taking some Christmas vacations, so I wish everyone a happy Christmas and a happy New Year. We will continue our series of lectures next year. Thank you very much.


