00:10 Introduction
02:23 How to? Supply chain lectures
04:22 The Quantitative Supply Chain Manifesto
06:47 All possible futures
17:01 All feasible decisions
21:52 Economic drivers
30:42 Robotization
35:41 Supply Chain Scientists
40:22 From vision to reality
41:56 The myth of the supply chain maturity
45:30 In conclusion
46:13 Questions from the audience
Description
The Quantitative Supply Chain’s manifesto emphasizes a short series of salient points to grasp how this alternative theory, proposed and pioneered by Lokad, diverges from the mainstream supply chain theory. It could be summarized with: every single decision is scored against all the possible futures according to the economic drivers. This perspective gradually emerged at Lokad as the mainstream supply chain theory, and its implementation by (nearly?) all software vendors, remains challenging.
Full transcript

Hi everybody, welcome to the Supply Chain Lectures. I am Joannes Vermorel, and today I will be presenting “The Quantitative Supply Chain in a Nutshell.” For those of you who are watching the stream live, you can ask your questions at any point via the YouTube chat. I will not be reading the questions during the lecture; however, at the very end of the lecture, I will go back to the chat and start with the questions from the top and do my best from there. So let’s proceed.

I will start with a quote from one of the former French presidents, who said that there were three paths to wealth: the quickest was with gambling, the most pleasant one was with women, but the surest one was with technicians. Obviously, in this series of lectures, we are opting for the third option. I believe that there is a grain of wisdom in this quote. Technique is a powerful way to do more of certain things, to be better at certain games, but it can also be quite distracting. By technicians, he meant not only people dealing with technical stuff, like engineers, but also those dealing with processes and workflows, the MBA type of technicalities.
When we tackle supply chain challenges, we have to be very mindful of whether what we are bringing to the table contributes to addressing the core problems or is just a feel-good distraction.

For today’s lecture, I will unfortunately be leaning a bit on the persuasion side. The challenge is that if you have a problem statement, you can prove that you have a solution that is superior for this very problem. However, can you prove that you have a superior kind of problem in the first place? That is much more challenging intellectually.
One of the main criticisms that I brought up during the previous lecture is that supply chain is a wicked problem at its core. Thus, the way we have to look at it is difficult. Today, I will try to bring a set of requirements that I believe to be essential if we ever want to have any hope of delivering something satisfying for supply chain. However, I can’t really prove that any of the elements that I’m bringing to the table is truly required. There is an element of belief, and also an element of high-level understanding. Another aspect of belief is that unless you have a solution to present in front of your requirements, all you have is wishful thinking. So I would ask you to suspend your disbelief for one or two more lectures, so that we focus on the very nature of the problem and the elements that are highly desirable for a solution to become eligible for good supply chain practice.

So let’s proceed. A few years back, Lokad had already pioneered its relatively atypical way of serving its own clients. At the end of 2016, I decided to consolidate a short series of salient points that I believe diverge considerably from the mainstream supply chain theory. I wanted to use those five points as a way to present how the quantitative supply chain differs from the mainstream supply chain. I apologize for the terminology being a bit unfortunate because even the mainstream supply chain theory is also very much quantitative, but I decided to add another adjective to clarify the distinction between the quantitative supply chain theory and the mainstream supply chain theory.
These elements that I will be listing are not exactly foundational; they are more like a checklist of things we need to address if we want to have any hope of succeeding. These elements include:
- All possible futures: We need to look at many futures, not just one future.
- All feasible decisions: When I introduced the definition of supply chain as the mastery of optionality, these decisions are the options I was referring to.
- Economic drivers: The idea that we are going to count the dollars of error, not the percent of error.
- Robotization as a requirement for management control: It may seem paradoxical because you would think that robotization implies losing control, but the proposition is that it is the exact opposite – you need robotization if you want humans to be in control of anything as far as supply chains are concerned.
- Supply chain scientist: At the end of the practice, there should be one person who has ownership of the numerical results of the supply chain or the quantitative performance of the supply chain.

Let’s have a closer look at each one of these five points.
First, the idea is that we need to look at all possible futures. Why do we even need to look at the future in the first place? We need to look at the future because everything takes time. We can’t 3D print everything instantly, and even if we could, we would still have to transport things. So everything takes time, which means that whenever you’re taking a supply chain decision, such as deciding to produce or purchase something, you do that because you’re looking ahead and anticipating a future state of the market where there will be some kind of demand for those products. You then work your way back and make a forecast of a kind, optimizing your supply chain accordingly.
We need to have this look-ahead and these forecasts, which are just the mathematical flavor of intuition. But what kind of forecasts are we talking about? The forecasts that have been completely dominating the supply chain practice during the 20th century and the first part of the 21st century are the classical time series forecasts, which are profoundly flawed in my eyes in several ways. The first way is that this approach completely disregards the idea of uncertainty. My proposition is that uncertainty is completely irreducible, and whenever you’re dealing with supply chains, the future can never be forecasted perfectly. The idea that you can have 99% forecast accuracy is nonsense. Even when looking at water consumption or electricity consumption, it is very challenging to achieve forecasts with this degree of accuracy.
When looking realistically at supply chains and considering, for example, a product in a store that sells only one unit a week for a given product in a given store, there is no hope of ever achieving sub-percent accuracy. The question doesn’t even make sense. So, uncertainty is irreducible. If we wanted to have a bigger proof of that, just look at the year 2020. We had a massive worldwide pandemic wreaking havoc all over the place across supply chains. It’s just not possible to forecast those sorts of things from a classical perspective where you have a number and say, “this is it, this is the future.”
Instead, what you can have are probabilistic forecasts. The idea is that all futures are possible, but they’re just not equally probable. That’s the essence of probabilistic forecasting. It’s the idea that you can have a statistical method that, instead of pretending to have the perfect forecast for exactly how things will play out in the future, just says, “I have all these possible futures; some are more likely than others.” This approach embraces the irreducible uncertainty. Many of the situations where people tell me, “you can’t forecast that,” the answer is, “yes, I can.” I cannot give you a correct classical forecast, but I can certainly have a perfect probabilistic forecast.
The extreme example of this would be lottery tickets. I can establish the exact odds that any particular ticket is the winning ticket. I don’t know which one is going to win, but if the game isn’t rigged, I can have a perfect probabilistic forecast that reflects the uniform probabilities for all the tickets. That’s exactly what a probabilistic forecast means; it means that you embrace the fact that although you don’t know the future perfectly, you know a lot about the future. When we say we have probabilities, we know a lot of things. For example, I can say that at any point in time, there is a tail risk of a massive disruption in the market. I don’t know exactly where the risk will be coming from; maybe it will be a pandemic, a stock exchange crash, a war, or a new tariff like the one that President Trump introduced. It can be many things that disrupt your supply chain, and if I had to assess the tail risk at any point in time for any supply chain, it’s several percent of having a massive drop for the next quarter. Again, it’s not magic; it’s just a very reasonable assumption to make about the future. With the proper statistical tools, you can have something much more elaborate. All the areas that are uncertain require a forecast, and a probabilistic forecast at that. Demand is not the only area that needs a forecast. For example, all the areas where you have uncertainties require a forecast.
This could include forecasting future demand, but also future lead times, future returns in e-commerce, uncertain production yields in primary production sources like mining or farms, probabilistic failure or scrap rates in quality control for biological processes, and repairs of parts. There is a large variety of areas where you have uncertainty, and all those areas deserve a forecast. A good supply chain practice is to embrace the need to think of all the possible futures with their respective probabilities, looking at all the things that need to be forecasted. It’s not just demand.
For example, we can even look at things like commodity prices. Obviously, if you could accurately forecast the future price of a commodity, you would just play the stock exchange and not run an actual supply chain. However, certain commodities are much more volatile price-wise than others, and that means that the sort of risk that you carry when dealing with these commodities can be optimized with the proper models by having probabilistic forecasts in your arsenal of tools.
Another element is that it’s not just your own possible futures; all those possible futures are not independent. They have strong dependencies, and that’s also something where the mainstream supply chain theory is really lacking. They look at the demand forecast as if it was completely independent from everything else happening in the supply chain. Even to this point in time, we still have prospects that come to me and ask if Lokad can do a 12-month ahead forecast for a specific product.
For example, let’s say we are dealing with a sporting brand and they ask for a tracking backpack. Can we forecast how much demand there will be during the next 12 months? My basic answer is, “it depends.” If you are just selling one backpack, then maybe you will have a certain amount of demand. But if suddenly you decide to vastly inflate your assortment and introduce ten more variants of the same backpack with nearly the same price point, size, and characteristics, plus or minus a few pockets and widgets, you’re not going to multiply your demand by a factor of ten just because you introduced ten more products that are very similar. Yet, when we look at the classical forecasting perspective, there is nothing that would prevent the forecasting model from radically inflating the demand figures if you just increase the number of products to be forecasted. So, that doesn’t make sense, and that’s why we have these futures. They are not only characterized by irregular uncertainty, but also by the dependencies that exist between them. We need to have tools that can apprehend all those changes.
As a concluding thought, forecasts are essential if we want to have any hope of optimizing anything, simply because we need to look ahead. However, we need to keep in mind that they are just educated opinions about the future.

They are not real, in the sense that the quality of your forecast has no direct consequences on your supply chain. In many companies, people focus intensively on improving the forecast, but my question is: to what end? If you think that optimizing the forecast immediately translates into better supply chain performance, my proposition for you is that this is a delusion. It is not true, not even remotely.
The only things that actually improve a supply chain are the decisions that have a tangible, physical impact on the supply chain. By decisions, I mean things like buying one more unit from a supplier, moving one unit of stock from one location to another, or raising or lowering the price for any product you’re selling. These actions have real, tangible consequences for the company.
On the contrary, forecasts are just educated opinions about the future. It’s better to have a more fine-grained opinion about what the future will look like, but the only things that really matter are the decisions. The proposition I have for you is that supply chain practice should be completely oriented toward the generation of those decisions, as that is the only thing that matters. The idea that you can have something like a forecasting or planning department is, to a large extent, misguided. Forecasts are only there to educate your guesses when it comes to making better decisions.
It’s very dangerous and misguided to separate the forecasting part from the optimization of decisions. By the way, when I say feasible decisions, I mean that the decisions should be compliant with all the physical constraints present in the supply chain. Any supply chain has non-linearities all over the place. For example, you can have minimal order quantities, maximum shelf space in a store, and maximal volume or weight capacity in a container or truck. You can have more subtle non-linearities, such as expiration dates, or the fact that certain parts in aerospace come with flight hours and flight cycles, requiring scheduled repairs.
You can have all sorts of problems, such as some goods, for example in fresh food, not being able to travel in the same truck. Or, at least, you need special trucks because they can’t be transported at the same temperature. You either need multiple compartments or multiple trucks. There are plenty of constraints that limit feasible decisions.
What do I mean by feasible decisions? I’m pointing out this term because it doesn’t make sense to say that the perfect quantity to replenish a store with is 1.3 units of a product. This is not a feasible decision; it’s going to be either one unit or two, but you can’t have 1.3. You need to have something that is immediately actionable from a very mundane perspective, and that’s what feasibility refers to.
Now, if we look at every single feasible decision and all the possible futures, the question is: how do we assess which decision is the right one?
We have to consider the economic drivers. The idea is that percentages of error don’t matter; only dollars of error and reward matter. There is a grand illusion that if you optimize percentages, you will actually do something good for your company. This is not true; I believe it is deeply misguided.
If you want an example, let’s look at service levels. What does it mean to have a super high service level? I frequently hear prospects say they want a 99% service level. We certainly can deliver that, but you just have to stockpile like crazy, which will result in immense inventory write-offs and abysmal profitability. It’s a trade-off, and it’s not just any trade-off – it’s an economic trade-off. In something as simple as service level, there is a trade-off between the cost of inventory on one side and the cost of stock-outs on the other.
The idea is that if we step back and look at these economic drivers for every single decision, we can assess the outcome. We can take one decision and, for one possible future, look at the outcome of this decision for that particular future. We can evaluate its outcomes in dollars by looking at the economic drivers.
What do I mean by economic drivers? I mean all the drivers that are shaping the performance of your company. The first circle of drivers is very straightforward – things you will find in accounting books, such as the cost of materials, selling price, carrying cost, transportation costs, and transformation costs. You have to pile up all these costs and then subtract them from your selling price to calculate your cost budget. These are the first circle of drivers, the very obvious ones that you can literally find in your ERP or accounting software.
However, these costs on their own are not sufficient. If you just consider them, you end up with a very short-sighted financial perspective. You need to include the second circle of economic drivers, the ones that do not exist in your system, at least not explicitly. These are typically the second-order effects of your supply chain decisions. For example, most of the time, if you have a stock-out, there is no stock-out penalty. Maybe if you’re a big brand selling to a large retail network like Walmart, you have a service level agreement and penalties if you don’t hit certain targets, but this is not very frequent. Even when you have penalties, they don’t naturally reflect the real costs you’ve inflicted on your clients.
The idea is that we need drivers that represent the second-order consequences of your actions, both positive, such as generating extra client loyalty, and negative, such as generating disloyalty and giving an incentive to your clients to go elsewhere for an alternative. This is obviously problem-dependent. For example, if you’re a fashion brand and you give a discount at the end of the season, it costs more than just the immediate loss of the discounted dollar. You’re creating a habit for your clients, who will expect the same discount next year. This illustrates the short-term impact and the long-term impact of building habits and expectations among your customer base, which is what I’m talking about when I mention the economic drivers of the second circle.
Done right, financial optimization is not short-sighted. However, if you do a naive financial optimization, you end up with a lot of nonsense, which is true for any naive recipe when dealing with supply chains. Economic optimization is essential because, without it, you don’t even have a target for your optimization. The idea of optimizing percentages doesn’t work; you want to optimize dollars. Unless you’ve consolidated all those dollars of reward and cost under a single umbrella, there’s nothing to optimize from a quantitative perspective, which is what’s of interest in this series of lectures.
We need those dollars, otherwise we can’t even start optimizing. My proposition for you is that if your company has not started to have a unified financial framework to drive its supply chain optimization, it hasn’t even started yet. If you have dozens of teams dealing with percentages, service levels, and other non-monetary metrics, it’s an illusion of performance. Only dollars matter – dollars, euros, or yen – but you need a monetary account.
These economic drivers have another very important purpose that is frequently overlooked. The first purpose is to drive the numerical optimization in a very mechanical way. The second purpose of these drivers is to enable white-boxing, which I will return to in a later lecture. The idea is that for every single decision, we are going to look at all the possible futures, assign the economic performance of the decision, average out the economic performance of decisions across all the possible futures, and then sort all the decisions from the one that has the highest return on investment (ROI) to the one that has the lowest. Obviously, we want to stop making those decisions when there is no profitability anymore. However, we need some kind of transparency and understanding with regard to why we are picking those decisions rather than other decisions. Here, those economic drivers prove themselves to be very valuable because they can tell us the “why” that is behind any decision that is going to be generated by a system, practice, or software.
The idea is that you will be able, with economic drivers, to look at every single decision and have a few key performance indicators (KPIs) expressed in dollars, explaining why this decision is actually a good one. Conversely, for a decision that is not taken, you can look at the drivers and assess why it’s not a good decision.

With these three building blocks, we have everything it takes to start the practice. We look at all possible futures, all possible decisions, and challenge every decision against all possible futures, scoring them in dollars and ranking them.
To make this real and effective, the mindset needed is complete end-to-end robotization. The reason why you need complete end-to-end robotization is to bring management back in control. It may sound odd at first because, if you robotize, how do you get anybody in control? It has to do with the nature of supply chains, which are very complex, distributed systems with many sites, products, clients, software pieces, people, and vehicles.
The alternative to having a robotized process to generate all those decisions that need to be taken on a daily basis is to have an army of clerks using an ocean of spreadsheets. The problem is that if you’re managing an army of clerks, whenever you want to change anything in your supply chain, it takes six months for the change to sink in because you will have to deal with many people that you will have to retrain and check that they really understand the new strategy and rules.
Robotization is the idea that if you can implement an end-to-end numerical recipe that generates all those mundane decisions, you can avoid this delay. I’m talking about all the mundane decisions; I’m not talking about decisions such as whether to start a new plant in a country or open up a new market for the company. Those decisions, you don’t take them on a daily basis. You take them a few times a year, and it’s perfectly fine to have a lot of people thinking about them. But for every single SKU that you have in your supply chain, you have half a dozen decisions that need to be made every single day. Should I produce more? Should I bring more? Should I displace the stock that I have somewhere else? Should I move the price up or down? Should I even get rid of this stock that is serving no purpose and is just taking up space in my warehouse or store? Even deciding to do nothing, if you have a SKU and you decide to do nothing particular today, is already a decision. So, considering the scale at which modern supply chains operate, my belief is that one needs end-to-end robotization if we want to have any hope of being agile.
There is also another essential angle, which is that it’s crucial to have end-to-end robotization if we ever want to have something that is capitalistic and accurate. This will be the topic of my next lecture, but the short version is that you do not want to treat your supply chain division as operating expenses (OPEX). You want to treat your supply chain investment as capital expenditures (CAPEX). All the efforts you’re pushing on supply chain should be accurate, and you want to make your supply chain a capitalistic asset of the company. The only way to do it is through robotization; otherwise, the opposite is just an army of clerks that you have to pay every single day to do the same thing repeatedly.
This brings me to the question of who should be in charge of robotization and the software that is doing the clerical work in place of an army of clerks.

Who should be responsible for those numerical recipes? Who should take ownership of those results? The classical answer, “we have a system, the system is responsible for that,” I believe, is misguided. A piece of software, even if it’s a very expensive enterprise software, is never responsible for anything. It’s not self-aware. Despite what people might say about AI, we are not there yet. What we have are glorified fancy numerical recipes, and they can already deliver tremendous value for your company.
Somebody in your company or outside of your company needs to take ownership of the quality of those numerical results that will drive your supply chain in a very mundane fashion. The practice that we have pioneered at Lokad is the idea of the supply chain scientist. The supply chain scientist concept was born from my early failures when I was attempting to address the problem with data scientists. The issue with data scientists is that their commitment lies in the technicalities. Remember the first quote about the surest way to ruin is with technicians? That’s exactly my perspective nowadays when people tell me about data scientists trying to solve supply chain problems. That’s a very short path, with very little uncertainty about where you’re actually heading, not that you will have great results at the end of the journey. The supply chain scientist is the person who is going to take ownership of generating real-world decisions, and this person has to pay attention to the most minute details of your supply chain. For example, if one of your warehouses was flooded last year and for three weeks nothing flowed through that warehouse, completely distorting the seasonality profile, you can’t dismiss that as just a detail. It doesn’t challenge the core validity of the mathematical model. The supply chain scientist’s perspective is that it does matter. If I end up taking poor decisions for this warehouse because an operational accident in the past introduced severe biases in my historical data, it matters. All of that matters, whether it generates dollars of reward or dollars of cost.
If we look at this illustration with two types of scholars, Indiana Jones, who is supposed to be a scholar and researcher, and Windle Poons from Terry Pratchett’s works, the reality of these two fictitious characters cannot be more profoundly different. The fundamental difference between them pretty much reflects the difference between a supply chain scientist and a data scientist. As a litmus test, you can ask yourself, does the CEO care? Is the CEO of the company going to challenge you as the supply chain scientist on what you’re doing? My experience of running Lokad for over a decade is that I now regularly meet with the CEOs and boards of my clients, and they challenge me on the fundamentals of their supply chain and how we are bringing dollars of return.
The questions do not revolve around whether we use support vector machines or gradient boosted trees. The questions are about the path that ensures the supply chain is a valuable asset that can outcompete the rest of the market.

I presented five points as requirements, not the actual solution to the problem. They are just a list of elements that, if not properly addressed, mean you have not even really started working on anything that would meaningfully improve or optimize the supply chain, at least not in a quantitative fashion. There are plenty of non-quantitative optimizations, like better equipment, better hiring policies, or well-thought-out financial incentives for your teams.
There is a full detailed plan of the upcoming lectures on the Lokad website at lokad.com/lectures. We will have to cover a lot of topics, including different perspectives, concepts, and paradigms, especially related to programming methods, tools, and practices. There is a significant amount of material to address, and all of these concepts will be introduced to help fulfill the five points I presented earlier. Without these, the approach simply will not work.

Now, to address a tangent, some people have challenged me by saying that the vision I present is so different from what they are currently doing. They argue that it is too advanced, and they prefer to take it slow, improving incrementally before considering this quantitative supply chain approach. However, I believe this “crawl, walk, run” approach is a fallacy. Progress is often non-incremental and disruptive. For example, when Amazon decided to become a cloud computing provider, they made a significant leap from selling books online to offering on-demand cloud computing resources. This was not a gentle, step-by-step progression; it was a disruptive shift.
Similarly, there is the famous quote from Henry Ford, who said that if he had asked his clients what they wanted, they would have asked for faster horses. The point is that if we accept the idea that the requirements I have listed are necessary, and most companies haven’t even started looking at the problem from the right perspective, then our starting point with most clients is that almost no one has any maturity in this area. It is an illusion to think that larger companies with large divisions optimizing the wrong metrics possess any real maturity in supply chain management.
My message to the audience is not to consider yourself immature just because you are not doing what other companies are doing, especially with regard to the size of their respective bureaucracies. From my perspective, this says very little about their effectiveness. The companies I see with the most maturity are typically small, agile, North American e-commerce companies that are digitally focused. They may not have massive teams of data scientists but instead have a few people with the right mindset and appropriate numerical recipes.
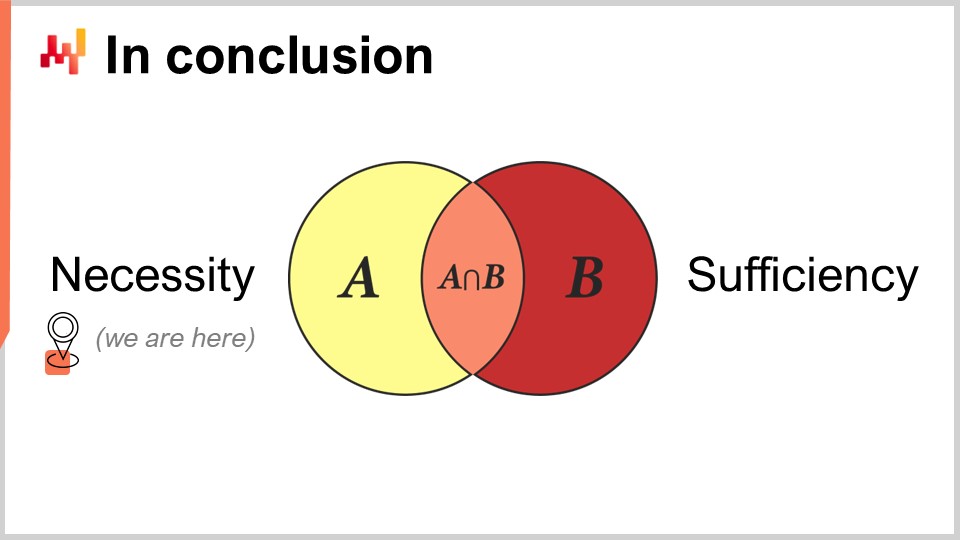
In conclusion, I have covered aspects related to the necessity side of the problem. In the next lecture, we will start to look at the sufficiency side of the problem, focusing on our problem statement and the solution. However, it is crucial to begin with the problem statement side, as it allows us to understand whether the solution we are presenting is valuable or simply a solution in search of a problem.

Thank you very much for your time today. Now, I will address the questions.
Question: I enjoyed the subtle Dune reference.
I appreciate that you enjoyed the Dune reference. The main characters in the book have the ability to see all possible futures, which provides them with superior strategic abilities. This metaphor is quite fitting for supply chain management. If you can examine all possible futures, even if you don’t know exactly which one will occur, it gives you a significant advantage over competitors who are only considering one possible outcome.
Question: Would you please elaborate more about the second-order drivers?
When I say “second order,” I am referring to second-order consequences. In supply chain management, we deal with humans and complex systems, not just simple physical systems with predictable trajectories. People can adapt, and we must consider their actions and reactions.
For example, in the past at Lokad, we had a client where we suggested specific purchase order quantities. However, we noticed that the client ended up placing orders with significantly higher quantities than what we recommended. It turned out that when the client received the goods, the teams in charge of reception would recount the items to ensure they matched the initial order. If the received quantity didn’t match the order, their system had a peculiar limitation: they could either cancel the entire purchase order and send back the merchandise, putting their production line in jeopardy. What was happening was that they were changing the quantity of the original purchase order so that it matched the quantity being received. Over the years, some smart suppliers had discovered this unique property of the ERP system. When they were nearing the end of the quarter and hadn’t achieved their targets, they knew they could push whatever they wanted to this client, who would take it and pay the invoice without any questions or complaints.
This is an example of what I call a second-order effect. You have a seemingly trivial, mundane aspect of your ERP, but then you have smart humans in the loop who game the system. This is bound to happen whenever you’re dealing with humans, as they can think and react to whatever you do. The idea of second-order consequences is that you must consider the consequences of the consequences. It could even be the fourth or fifth order – you have to think about the cascading consequences. It’s a challenging intellectual game, but if you don’t take second-order consequences into account, you may end up making poor decisions.
As for the second-order economic drivers, it’s essential to put a dollar value on them, although it can be difficult. The key is to be approximately correct rather than exactly wrong. It’s better to have a ballpark estimate that makes sense rather than precise calculations that lead you astray.
Question: What are the techniques used in complete robotization?
There are numerous techniques for complete robotization, which we will cover in the upcoming lectures about programming paradigms. Although we are discussing software, we need to consider the core design properties that are most desirable for achieving robotization. The primary goal is to create production-grade software, not necessarily AI. You cannot achieve zero percent forecasting error, but you can aim for zero percent insanity.
By “insanity,” I mean something that would jeopardize your entire company. For example, Target Canada went bankrupt due to supply chain optimization gone awry, and Nike faced a disaster in 2004 when one of their supply chain software solutions, which was a competitor of Lokad, almost led to the company’s collapse. So first, we will cover this topic in the next lecture, but it will take us a bit of time to get there.
Question: In your forecast, if we try to encompass so many progressive variables, we would need to develop models ourselves, and it may become simulations. Any thoughts?
There is no clear difference between an accurate simulation of the future and a probabilistic forecast. These are two different flavors of numerical recipes for apprehending the future. Whenever you have a probabilistic forecasting model, you can generate trajectories that represent the future. You take your probabilities, draw a deviate, create a fictitious observation, relearn your model, rebuild your probabilities, and iterate. The distinction between simulation and statistical modeling becomes thin, especially for models suitable for supply chain purposes. To a large extent, they completely overlap.
Question: Are the solutions you developed service-based or a combination of both? What is your opinion on this approach for the future of supply chain?
At Lokad, our perspective is to deliver supply chain performance expressed in dollars. There is an immense amount of complexity in this domain, and just like uncertainty is irreducible in forecasting, the complexity is irreducible if you try to have a software product that tackles all problems at once. You need a meta-solution for the problem. The approach taken at Lokad is to acknowledge the need for human intelligence, specifically supply chain scientists. I believe it is unrealistic to think that AI can comprehend the challenges of a modern supply chain.
We need smart, experienced people with the right skills to be effective in their jobs. Lokad has developed a product with the goal of making supply chain scientists productive and exceedingly reliable. The challenge is providing the right tools for these supply chain scientists. In summary, Python is not the solution, and as we move forward in these lectures, you will see that there are profound problems with most generic programming languages. These design problems make them unsuitable for addressing supply chain problems in a satisfying manner. We will have to get into the fine print because there is a lot of nuance in what I mean by “production-grade” and the “production-readiness” of the solution. Remember, that’s the zero percent insanity we want, because as long as you have an insane robot that negatively impacts your supply chain, it just cannot work. That’s what we need to address first.
Question: Often quantitative approaches require us to quantify what was not quantified yet or what was sitting in Excel spreadsheets, not in ERP systems. What is the most efficient way to deal with this problem? How can this additional information be gathered so that it can be as reliable as information from the ERP systems?
There are two distinct problems here. First, there is the status quo, where the problem with quantifying rewards and errors is that it is politically very tough. A lot of people in large organizations have strong incentives not to discuss dollars of returns or rewards, because otherwise the company would realize that they have zero added value. So, there are many things that are not quantified just because there are strong political forces playing against it.
To make this more concrete, when Lokad started working for a retail network to optimize stock in stores, we realized that the stock served two radically different purposes. The first purpose was to service clients properly, requiring a certain amount of stock. The other purpose was for the store to look full and appealing, which required an additional amount of stock. We had a quantity of stock expressed in euros for this large retailer and said that half of the stock was needed for servicing purposes and should be carried by the supply chain, while the other half was needed for merchandising purposes and should be the responsibility of marketing. Obviously, marketing, who suddenly had a massive inventory line entering their budget, was not happy with this idea.
So, first, we need to address the fact that it’s very tough to establish rules for quantifying dollars of reward and cost, and these rules should apply to everyone equally. This is difficult to achieve, and many people in organizations have a vested interest in keeping things this way. We have another type of problem, which is actually much easier to address: shadow IT. The issue with ERPs and similar software, as you can see in the Lokad knowledge base on ERPs, is that it’s very difficult for ERP vendors to cover all situations. For example, you might have minimum order quantities (MOQs). How do you represent that in an ERP? It really depends. The MOQ can be at the product level, the order level, or sometimes a combination of both. It can even be more complicated, such as in textiles, where the MOQ is defined by the amount of fabric in each color.
The problem is that, for ERP vendors, it’s mind-blowingly difficult to represent all of that. As a result, people buy an ERP and then realize it does not let them represent everything they need, so they fall back on Excel spreadsheets. I believe that’s precisely the role of a good IT department: to build and deliver the missing bits so that shadow IT doesn’t remain shadow IT, but instead becomes small extra bits of in-house extensions. In a sense, it’s good to have an ERP, and my advice is not to customize your ERP but to do something on the side. It’s much easier to maintain rather than going the “Frankenstein” way on top of the ERP.
Thank you very much, everybody, for watching. The next lecture will be next Wednesday, same day, same time. See you soon. Goodbye.
